![]()
|
Let op. Dit programma werd een paar jaar terug soms wel dagelijks vernieuwd. Met name de installatie-procedure werd enorm vereenvoudigd. Via Help /update wordt de actuele versie van het Python script geïnstalleerd. Met wat geluk verloopt de installatie van de benodigde python bibliotheken automatisch bij u. Maar als dat niet lukt kunt u wat commando's onder de Windows opdrachtverwerker cmd.exe geven. Dit artikel helpt u op weg. |
![]()
TkAstroDb is een open source programma van Tanberk Celalettin Kutlu, waarmee astrologisch onderzoek gedaan kan worden met de gegevens uit de Astrodienst database (ADB). Het gaat om een Python script, dat in principe op de meeste besturingssystemen met een Python interpreter zou moeten lopen.
Voor het gebruik van het Python programma TkAstroDb is geen speciale kennis van Python vereist. Maar mocht u het met ./run.py opgestarte Python script willen aanpassen dan vindt u de Python documentatie op http://docs.python.org.
TkAstroDb is ontworpen om statistisch onderzoek te doen op de voor onderzoekers vrijgegeven AstroDienst uitdraaien. In de praktijk komt dat neer op het vergelijken van de astrologische eigenschappen van specifieke ADB categorieën. U vindt die uitdraaien op http://www.astro.com/adbexport/ van de Astrodienst Database (ADB).
Nog niet zo lang geleden stonden alle sinds 2017 gepubliceerde ADB uitdraaien online. Maar sinds 2022 zijn recente uitgaven uit de http://www.astro.com/adbexport/ map verdwenen. De WayBack Machine heeft die onverwachte beleidsverandering helaas niet geregistreerd. ADB onderzoekers kunnen die “verouderde bronnen” ongetwijfeld nog wel opvragen bij de ADB webmaster Alois Treindl. Het gaat immers om algemeen beschikbare ADB export bronnen tussen 2017 en 2022. Ze werden gebruikt om de op astrology-research.nl gepresenteerde analyses van de ADB categorieën statistisch te analyseren.
Als standaard methode vergeleken we de astrologische eigenschapen van een specifieke ADB categorie (onderzoeksgroep) met die van de ADB als geheel (controlegroep). Belangrijke statistische waarden als effectgrootte van planeet in teken of huis voor een bepaalde ADB categorie, als ook hun statistische relevantie (binomiale p-waarde) gezien de grootte van de onderzochte categorie, konden per hemelstand worden berekend. De uitkomst van al die metingen en berekeningen geeft TkAstroDb in een gemakkelijk te analyseren excel rekenblad formaat aan. Belangrijke statistische waarden die TkAstroDb niet berekent zijn op die manier gemakkelijk te achterhalen.
TkAstroDb kan de van AstroDienst ontvangen XML bestanden omzetten in een JSON database, die u zelf kunt bewerken. Zo kunt u een nieuwe categorieën invoeren en records bewerken. Op die manier is een onderzoeker niet afhankelijk van de mening van ADB editors met betrekking tot de vraag wie wel of niet tot een bepaalde categorie behoort. Zie: ADHD als voorbeeld .
De resultaten van dit nog steeds lopende onderzoek ziet u terug in ADB stats. Het gaat inmiddels om meer dan anderhalf GigaByte aan statistische data over ADB categorieën. We geven daarmee een antwoord op de vraag of bepaalde ADB categorieën als schilders, schrijvers en politici in astrologisch opzicht van andere groepen verschillen, waar die verschillen in de horoscoop te vinden zijn, hoe groot ze zijn en hoe groot de kans is dat de gevonden verschillen op de bemonsteringsfout berusten.
In artikelen als 79 Art Critics en The astrological profile of 1867 ADB astrologers werden de statistische resultaten van enige ADB categorieën besproken. Het doel ervan was om u te laten zien hoe statistici en wetenschappers deze astrologische data zouden analyseren. Dit artikel is meer op de praktijk gericht.
 U
moet onder Windows wel zelf een Python omgeving installeren.
Op http://www.python.org/downloads/
vindt u meerdere pakketten van Python versie 3.
U
moet onder Windows wel zelf een Python omgeving installeren.
Op http://www.python.org/downloads/
vindt u meerdere pakketten van Python versie 3.
Voor Windows 10 gebruikers raden we Python 3.7.2 aan, gezien een bug in de grafische user-interface onder Windows: http://bugs.python.org/issue36468. Door deze bug worden bij het selecteren van categorieën de al eerder gekozen categorieën niet rood gemarkeerd. En onder Linux kwam ik Python versies tegen die de Chiron statistieken niet konden berekenen.
Maar ik trof ook Python 3.8 versies aan die onder een Windows VirtualBox met Linux de 3D acceleratie van de fysieke videokaart als een mathematische co-processor konden benutten. Met soms wel drie tot vijf maal kortere rekentijden op de gevirtualiseerde computer.
Het is op zo'n virtueel computer systeem soms behoorlijk zoeken naar goed werkende videokaart resoluties waarbij de vensters nog netjes verplaatsbaar zijn. Maar dat tweaken en tunen was voor mij beslist de moeite waard. Een goed werkende configuratie (hier virtual box systeem) moet u natuurlijk altijd opslaan, want als een update verkeerd uitpakt kunt u altijd weer terug zonder alles opnieuw in te stellen. Herstel van de oude situatie kan dagen kosten en een USB stick os schijf is goedkoop. Het maken van backups is essentieel geldt al helemaal als u wetenschappelijk onderzoek verricht. Want de door u behaalde resultaten (inclusief bugs in de software) moeten natuurlijk wel reproduceerbaar zijn.
Momenteel (2024) gebruik ik op zowel op Intel als AMD systemen een Ubuntu 20.0.03 systeem met Python 3.8.10 onder VirtualBox . Hierin heb ik nog geen irritante bugs aangetroffen. Ook zonder exclusieve hardwareversnelling vanwege Micosofts Hyper-V deden moderne processors ongeveer 10 tot 25 minuten over het aanmaken van een controlegroep van 69317 personen uit adb_version_240703_1414.
Voor liefhebbers die de vaak frustrerende installatieprocedure (zie hieronder) willen overslaan zal ik een geanonimiseerde versie op het internet plaatsen: Ubuntu 20.04.03 TkAstrDb Kloon_.7zip met inlognaam sjoerd, wachtwoord tkastrodb. Deze versie bevat geen ADB databestanden. Als u na installatie van virtual Box op het vbox bestand klikt hoeft u alleen nog het netwerk aan te passen. NAT zal onder alle systemen werken, maar met een bridged adapter naar uw netwerkkaart benaderd u uw thuisnetwerk het snelst. Wilt u om veiligheidsredenen niet van het internet gebruik maken, maak dan gebruik van gedeelde mappen.
Alle Python versies staan op http://www.python.org/ftp/python/. Voor 64 bits Windows systemen (met Intel of AMD processor!) koos ik de Windows x86-64 executable installer van versie 3.7.2 (python-3.7.2-amd64.exe). Deze versie bleek onder Windows te werken. De 32 bits Windows x86 executable installer werkt op alle moderne Windows systemen (python-3.7.2.exe).
Mocht u Python na installatie niet aantreffen in Program Files, dan is dat normaal. Want standaard worden de uitvoerbare bestanden en bibliotheken in uw lokale programmamappen van de gebruiker (hier sjoerd) geïnstalleerd zoals het plaatje hiernaast laat zien.
Inmiddels (oktober 2020) zitten we op versie 3.9.0. Deze versie biedt betere ondersteuning voor SMP met meerdere processors. De berekeningen zouden dus sneller moeten gaan op gangbare processors. Maar we zagen ook dat de door ons gebruikte niet officiële Swiss Ephemeris bibliotheken nog niet voor Python 3.9 beschikbaar waren. En dan loopt u tegen deze foutmelding aan:
Zonder Swiss Ephemeris bibliotheken kan TkDbAstro niet werken. Voor Linux beval ik in 2020 daarom aan een oudere versie van Python 3.8 te installeren, naast de laatste Python versie die meestal al op Linux is geïnstalleerd.
Dat u meerdere Python versies naast elkaar kunt gebruiken geldt ook voor Windows gebruikers. Zo werkt de laatste Windows versie van de open source E-book manager Calibre niet onder Python 3.7.2. Het is dan slim om de laatste Python versie in het zoekpad te houden (Add Python to PATH) en TkDbAstro afzonderlijk onder Python 3.7 op te starten.
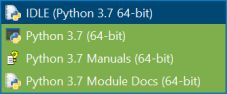 Hoe
doet u dat? Onder Windows kunt van de Python launcher gebruik
maken: Start / Programma's / Python 3.7 / IDLE (Python 3.7 64-bit). U
opent run.py in de map TkAstroDb-master met File / Open of File /
Recent files als het bestand al eerder geopend is. U ziet dan een
scherm de Python code die u met Run / Module of F5 uitvoeren kunt. U
moet in het begin altijd even wachten omdat TkAstroDb nog wat
bibliotheken installeert.
Hoe
doet u dat? Onder Windows kunt van de Python launcher gebruik
maken: Start / Programma's / Python 3.7 / IDLE (Python 3.7 64-bit). U
opent run.py in de map TkAstroDb-master met File / Open of File /
Recent files als het bestand al eerder geopend is. U ziet dan een
scherm de Python code die u met Run / Module of F5 uitvoeren kunt. U
moet in het begin altijd even wachten omdat TkAstroDb nog wat
bibliotheken installeert.
Een simpele aanpassing van de run.bat ook. Het voordeel van de pauze is dat u het beloop van de installatie aan de hand van (fout)meldingen kunt volgen. Pas het pad nog wel even aan.
Overigens kunt u Windows of Linux natuurlijk ook onder een PC emulator als VirtualBox draaien. Het voordeel hiervan is dat u langdurige berekeningen kunt pauzeren, opslaan (snapshot nemen) of tijdelijk op de vaste schijf kunt parkeren (de staat van de machine opslaan), om ze vervolgens gedurende de nacht weer te activeren.
Bij de deïnstallatie van vorige Python versies blijven vaak veel door de oudere versies geinstalleerde bibliotheken in de verborgen map site-packages zitten. Als u die niet meer gebruikt kunt veel schijfruimte vrijmaken door bestanden van oude Python versies in C:\Users\naam\AppData\Local\Programs\Python\te wissen. In de Windows Verkenner moet u daarvoor onder Beeld /Verborgen items zichtbaar maken aanvinken. Anders ziet u die verborgen AppData bestanden niet staan.
Wilt u meer controle over het proces, dan zijn er ook zip bestanden of een installatie op maat. Vergeet niet het PATH aan te passen. Controleer het pad door path op de cmd-prompt te typen. Maar als u de enige Python gebruiker bent is het wel zo gemakkelijk om alles in uw eigen gebruikersmap te installeren.
Het programma TkAstroDb bevindt zich op http://github.com/dildeolupbiten/TkAstroDb. De maker deed helaas niet aan versiebeheer. Oudere versies staan nog wel op https://web.archive.org. U kunt het best downloaden door op bovenstaande locatie rechtsboven op de groene knop Clone or download te klikken. En daarna op Download ZIP. U pakt het bestand uit op de locatie waar u het wilt gebruiken.
Het
TkAstroDb-master.zip dat verkrijgbaar was op
http://github.com/dildeolupbiten/TkAstroDb
is bijna 100 MB groot. Het grootste deel daarvan zit in de
subdirectory Eph dat uit 105 MB aan Swiss Ephemeris databestanden van
Astrodienst bestaat. Hier zit ook een submap Whl van Wheel, waarin de
gebruikte Swiss Ephemeris bibliotheken voor Windows staan. De andere
benodigde bibliotheken worden door TkAstroDb via het internet
opgehaald zodra u het programma start.
Dat was de bedoeling, maar het gaat ook wel eens fout. U moet in ieder geval online zijn om het programma in installeren of op te waarderen (via Help / Check for updates). Mocht het na een update misgaan, wis dan eerst het defaults.ini bestand en probeer het opnieuw.
Het Python script dat de bibliotheken aanstuurt is relatief klein. Het wordt opgestart met run.bat.
Ik heb het de opdracht pause zelf toegevoegd om fouten op te kunnen sporen. Want de eerste keer dat u het programma draait moeten allerlei bibliotheken van het internet gehaald worden. Zonder pause zult u die acties en eventuele foutmeldingen van het programma niet zien, omdat Windows het scherm met de meteen afsluit. En dat komt omdat doorsnee Windows gebruiker nu eenmaal niet van technische details houdt.
Een mail naar de ontwikkelaar Tanberk Celalettin Kutlu met bovenstaande uitvoer leverde het volgende antwoord op:
Na die quick fix bleek het installatieproces toch weer te blijven hangen en kwamen we tot de conclusie dat we maar beter met een Python 3.8.? konden blijven werken. En inmiddels is dat voor Windows Python versie 3.7 geworden.
Dit was de beoogde uitvoer van run.bat onder Python 3.8.? (niet onder 3.8.10, want die deed het op 22 Feb 2022 zelfs nog niet)
Nadat bovenstaande bibliotheken correct geïnstalleerd zijn start het Python programma vanzelf op. Gaat het op de een of andere manier mis dan kunt de benodigde bibliotheken ook met de hand installeren met de volgende commando's op de prompt.
U kunt deze opdrachten tijdelijk in run.bat (of onder Linux in dit bash script) plaatsen.
Daarna zal het programma onder wat oudere Python versies doorgaans wel opstarten. En zo niet dan doet u weer een nieuwe poging na het wissen van het bestand defaults.ini.
Maar u zult eerst een xml of json bestand als adb_export_200814_1910.xml in TkAstroDb-master\Database moeten plaatsen, voordat TkAstroDb er wat mee kan doen. Als de TkAstroDb-master\Database leeg is, en dus geen xml of json database bevat, reageert de TkAstroDb opdracht Database / Open niet.
De gezipte uitdraaien van de Astrodienst database staan of stonden eens in http://www.astro.com/adbexport. U moet aan Alois Treindl toestemming vragen om ze te gebruiken (pdf). De gezipte xml-bestanden zijn met een wachtwoord versleuteld.
Zodra u de database selecteert met het pop-up venster dat onder Database verschijnt, kunt u de door u gewenste ADB categorieën selecteren.
Waarschuwing: Bewerkt een plain text Python script niet met Windows Kladblok (notepad), want die doet zijn naam in negatieve zin eer aan. Ik gebruik daarom het open source Notepad ++ dat de programmacode netjes in beeld brengt, zonder in de war te raken van de regeleinden die onder Unix en de Macintosh computers gebruikt worden. Zie: Notepad bug Mac Unix. En maak natuurlijk eerst een backup van ieder bestand dat u verandert.
U kunt deze iedere keer aanpassen via het menu van de grafische interface onder Options / OrbFactor, maar u kunt ze ook aanpassen in defaults.ini bestand. Wilt u standaard een orb van 8 graden voor een conjunctie gebruiken, verander dan conjunction = 6 in conjunction = 8.
 Hetzelfde
geldt voor het favoriete huizensysteem (Options / House System).
Placidus is de standaardwaarde, maar u hebt de keus uit Placidus,
Koch, Porphyrius, Regiomontanus, Campanus, Equal en Whole Signs. Wilt
u liever Koch gebruiken dan zet u in defaults.ini:
Hetzelfde
geldt voor het favoriete huizensysteem (Options / House System).
Placidus is de standaardwaarde, maar u hebt de keus uit Placidus,
Koch, Porphyrius, Regiomontanus, Campanus, Equal en Whole Signs. Wilt
u liever Koch gebruiken dan zet u in defaults.ini:
Recent (maart 2021) werden ook de door de Swiss ephemerisis ondersteunde vedische methoden van tijdsberekening aan TkDbAstro toegevoegd. Ze staan vermeld in het bestand scripts/constants.py.
Ik ben persoonlijk geen voorstander van de introductie van nog meer hypothetische systemen, om problemen op te lossen die met een Keep it simple, stupid (Kiss) eenvoudiger op te lossen zijn. Want met een argument als: Onder mijn favoriete Babylonian (Kugler 3) tijdsdenken klopt het voor mij(n gevoel) toch wel, zult u uw minder bedeelde lotgenoten wel eerst tot uw briljante systeem van tijd waarnemen moeten bekeren. Maar waarschijnlijk hebben zij daar weer andere ervaringen mee opgedaan zoals de dichter Bredero al voorspelde: Het kan verkeren. En is dat dan toeval of niet? Hoe weet u dat zo zeker?
U start het programma op met python tkastrodb.py op de opdrachtverwerker CMD.EXE in de TkAstroDb directory. U kunt natuurlijk ook de run.bat met de muis in de Verkenner aanklikken. Onder Linux is de opdracht python3 tkastrodb.py.
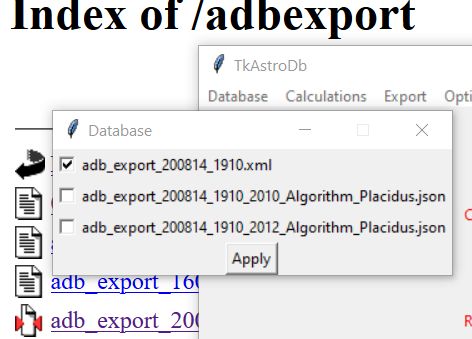
U selecteert de gewenste database onder Database. Er moeten daarvoor wel geschikte bestanden in de map TkAstroDb-master\Database aanwezig zijn, anders ziet u niets. Met Apply bevestigt u uw keus.
Zie het plaatje hierboven. Na een tijdje laadt de gekozen database en ziet u onder Display records nog een leeg venster. Dat komt omdat u nog niets geselecteerd hebt. Daarna volgt het proces van het selecteren van de gewenste horoscopen van Astrodienst. Het is wijs om uw selectie eerst vast te leggen (via Export) en daarna de berekeningen te doen.
Soms staan er meerdere ingepakte xml bestanden in http://www.astro.com/adbexport.
De readme zegt hier het volgende over:
U pakt de meeste actuele (full version en laatste update) zip-bestanden uit en plaatst ze in de Database map. Via de optie Database \ Merge and Convert (selecteer de meest actuele xml bestanden) destilleert TkAstroDb een actuele Json versie daarvan. Dat bestand (adb_export_200814_1910_&_adb_export_update_210209_1352.json) kunt u vervolgens gebruiken om met TkDbAstro of TkEnneagram allerlei astrologische berekeningen te doen.
 U
selecteert de gewenste ADB Categorieën en Rodden
Ratings. De Rodden Ratings kunt u gewoon aanvinken. Doorgaans
kiest u AA tot en met B(iografie) tijden, omdat de C(autious) tijden
en alles daaronder onbetrouwbaar zijn. Zie: Rodden
Rating.
U
selecteert de gewenste ADB Categorieën en Rodden
Ratings. De Rodden Ratings kunt u gewoon aanvinken. Doorgaans
kiest u AA tot en met B(iografie) tijden, omdat de C(autious) tijden
en alles daaronder onbetrouwbaar zijn. Zie: Rodden
Rating.
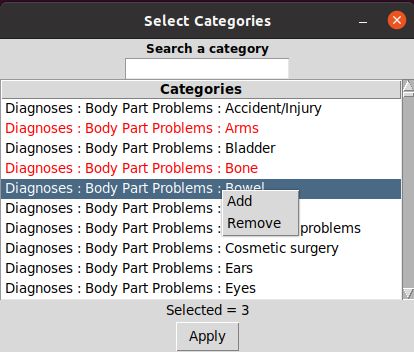
Voor de categorieën is de methode wat anders. U selecteert een of meer gewenste categorieën door er rechts op te klikken. Met Add wordt de gekozen selectie rood gekleurd en actief gemaakt. Met Remove wordt een rode categorie weer zwart en dus gedéselecteerd. De database blijft met iedere Remove intact. U verwijdert alleen maar een rood gekleurd item uit de selectie. Zodra u op Apply klikt wordt de gekozen selectie (het rode deel) toegepast in de TkAstroDb berekeningen onder het kopje Calculations.
Omdat de ADB 792 categorieën telt en u misschien niet altijd weet waar u het moet zoeken is het Search a category venster handig. Typt u daar poet dan komt u meteen in de betreffende categorie terecht (Vocation: Writers: poet). Maar als u daar writer typt en Enter geeft, komt u in de hoofdcategorie Vocation: Writers terecht, die allerlei soorten schrijvers bevat. Op die manier kunt hele beroepsgroepen selecteren en met Add aan de selectie toevoegen.
Een controlegroep kunt u aanmaken door in het Categories venster op Ctrl-A(ll) te drukken. Dan worden alle categorieën geselecteerd. U kunt dan gebruik maken van Rodden Rating AA tot en met C die data bekend veronderstelde geboortetijden bevatten. Gebruik geen data waarbij de geboortetijd onbekend is, want dan worden de 12 uur in de middag kaarten natuurlijk oververtegenwoordigd.
Als u ervoor zorgt dat de onderzoeksgroep volledig binnen de controlegroep valt, dus een deelverzameling is van de controlegroep, dan zijn de statistische berekeningen geldig. De te verwerpen NUL hypothese is dan dat uw specifieke selectie uit de ADB astrologisch gezien niet meer afwijkt dan een willekeurige steekproef uit de ADB van die grootte. U kunt dus beter geen AA tot en met C categorie vergelijken met een AA controlegroep, want dan ondermijnt u de rationale van de statistische berekeningen.
Nadat u op Display records klikt verschijnt na een tijd de gekozen lijst met records. Als de geselecteerde groep groot is, kan dit enige minuten duren.
Stel u wilt nagaan of een Zon, Maan of Ascendant in Ram vaker dan verwacht de diagnose ADHD krijgt. Dat zou zomaar kunnen gebeuren. De dokter of juf vinden uw kind best wel druk. Het mist een stofje in de hersenen. Maar een astroloog heeft er een alternatieve verklaring voor. Want dat fenomeen was al in de oudheid bekend. Het heeft te maken met Mars energie.
En wie weet vraagt u zich net als Trudy Lahue (1951) wel af of het ADHD verhaal misschien wel een modeverschijnsel is. Zeg maar Tijdsgeest, zoals ik in De documentaire serie Profiel en het enneagram (2010) al stelde in mijn relaas over de contrafobische zes. Sommige generaties zijn nu eenmaal wat drukker dan andere. Dan zou u ook geïnteresseerd moeten zijn in de constellaties van de langzame planeten. Maar wie weet wordt zoiets wel astrologisch bepaald.
Grote vraag: Hoe begint u zo'n astrologisch onderzoek? En waar vindt u de relevante data? En hoe onderzoekt u de feiten zonder dat een andere astroloog zegt: Ja, maar in mijn ervaring is het toch wel heel anders. Maar hoe doet u dat op een redelijke manier?
Dan kunt u het beste maar gaan schatgraven in de Astrodienst Database, de astrologische database waar iedere astroloog wel eens gebruik van maakt. Als die ander dan zegt, in mijn ervaring is het geheel anders, dan kunt u hem repliceren met: Wat heeft de astrologische gemeenschap daar aan? Waarom hebt u die data nooit eerder gepubliceerd?
U zou gebruik kunnen maken van de Astrodatabank research zoekmachine. Die laat uitgebreide zoekacties toe op astrologische constellaties, maar AstroDienst biedt geen mogelijkheden om die bevindingen statistisch te evalueren. U kunt op die zoek en gij zult vinden voluit speculeren dat toeval niet bestaat, maar zonder een simpele statistische evaluatie van uw geloof in het hogere blijft het daarbij. Uw zogenaamd kwalitatieve vondsten wordt dan een as you like it verhaal zonder enig wetenschappelijk belang.
Astrologen kregen een afkeer van toetsend statistisch onderzoek, omdat het steeds weer hun voorbarige interpretaties bleek te kunnen ondergraven. Maar is dat gebrek aan statistisch bewijs voor de astrologische stelling dat toeval niet bestaat nu een probleem van de statistiek of de astrologie? Zowel de astrologie als de statistiek maken zowel gebruik van wiskunde als van menselijke empirische ervaring.
Maar het statistisch onderzoek van grote groepen personen is helemaal niet zo gemakkelijk. Voor een aan u bekend individu kunt met enige creativiteit altijd wel een kwalitatief hoogstaande interpretatie op maat verzinnen, zoals een treffend Sinterklaasgedicht of een goede parodie van die persoon op een Oudejaarsconference. Met een een leuk verzonnen relaas wint er ongetwijfeld stemmen en applaus voor eigen publiek. Het bevordert zelfs de cohesie in uw groep. Het klopt weliswaar niet helemaal, maar dit is wel onze manier van denken.
Maar een rechter of historicus kan niet op die manier te werk gaan. Die zoekt naar harde bewijzen, niet naar leuk gevonden aanwijzingen en daarbij passende beeldvorming. En als de harde bewijzen ontbreken worden statistieken belangrijker. Als een bepaalde planeet aldoor op de plaats van het delict een bepaalde acte de présence geeft, dan kan dat geen toeval meer zijn. Dat is de kern van de astrologie. En ook op die manier spoort justitie boeven op.
Maar daarbij mogen ze natuurlijk niet op buitenlanders, vijanden van de staat en vermeend asocialen discrimineren. Want dat voert tot een tunnelvisie in een rechtstaat waarin iedere persoon een onschuldig open boek behoort te zijn totdat het tegendeel bewezen is. En dus moeten rechters weet hebben van de gevonden feiten en omstandigheden.
Een rechter die een slachtoffer van Putins schrikbewind vertelt dat hij gelijk heeft, maar toch van hogerhand veroordeeld moet worden, volgt de regels van een gecorrumpeerde rechtsstaat op. Maar hoe zit het met een astroloog die de meningen van de heersende astrologie betwist? Waar kan hij zich op beroepen? De gevonden astrologische werkelijkheid of de ideale astrologische werkelijkheid uit uw boeken? Of in het geval van Putin: De waarheden van de door hem beheerste Russische staatstelevisie en het ministerie van defensie? Of is er toch something rotten in the state of Denmark zoals Hamlet terecht vermoedde?
Om dergelijke vragen te beantwoorden moet u zelf onderzoek doen. Voor de statistische analyse van de astrologisch gevonden feiten is TkAstroDb ontworpen. Het gaat daarbij niet om mijn bijzondere ervaringen tegenover die van u en anderen, en de daaruit volgende meningsverschillen over hoe astrologie precies werkt, maar om de gerede justitionele vraag of we Pluto of een andere vermeend malefic planeet überhaupt wel iets kwalijk kunnen nemen. Want via de techniek van het kersenplukken - gebruik alleen wat je voor je cultureel bepaalde kokervisie nodig hebt - in kan iedereen wel zijn gerede zegje doen. Maar wat heeft een rechter of de lieve heer aan uw verhaal?
Een gemeenschappelijk onderzoek stond Lois Rodden, evenals de vele ander astrologische data verzamelaars voor ogen. Haar heilige idee was niet om te bekvechten over de implicaties van de door ieder weer anders gevonden gevonden feiten, maar door de diverse krachten te bundelen in een database waarin er op zijn minst consensus bestond over de betrouwbaarheid van de astrologisch gevonden feiten. Zo heeft het weinig zin om een astrologische kwesties met debatten over horoscopen met een onzekere geboortetijd te beslechten. Om die reden werd de Rodden Rating bedacht. Daar moeten we dus mee aan de slag. Maar nu terug naar ons voorbeeld.
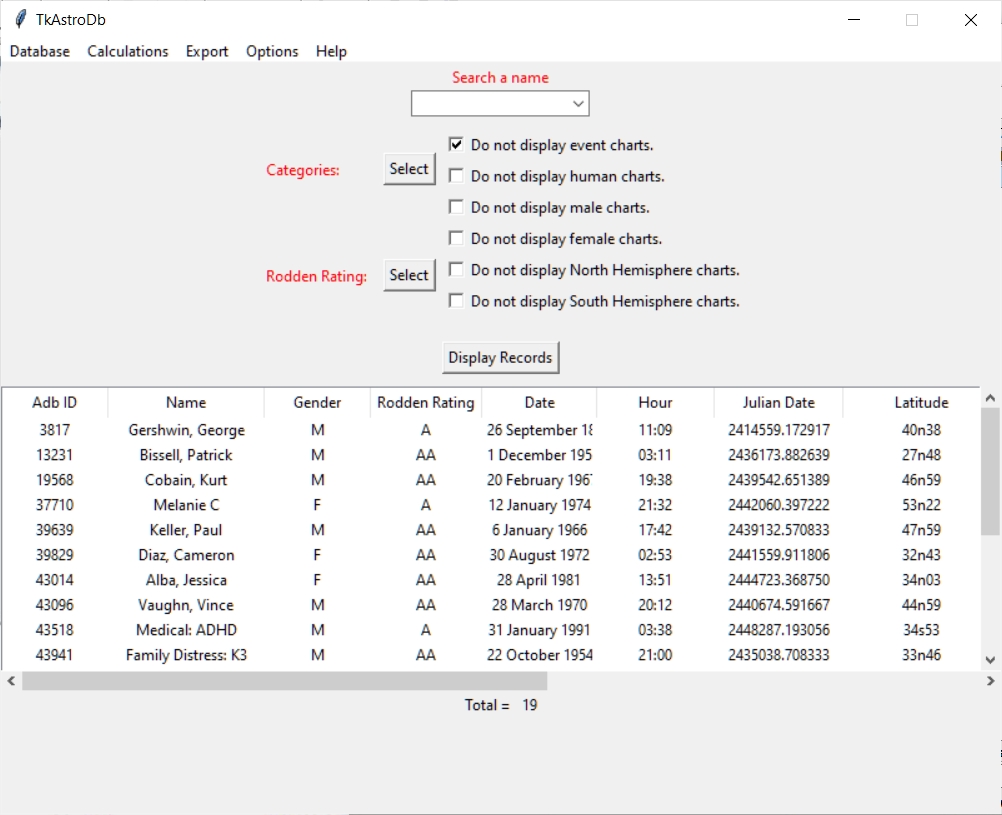
U bent geïnteresseerd in menselijke personen met ADHD, dus u begint uw selectie met Do not display event charts aan te vinken. Natuurlijk hebben aardbevingen geen ADHD, maar u wilt niet het risico lopen dat er per abuis een helemaal niet van toepassing zijnde horoscoop in uw selectie terecht komt.
U kiest voor de optie Do not display events charts als u personen onderzoekt. U selecteert Do not display human charts als u mundaan onderzoek doet. Recente versies bevatten ook Do not display male charts en Do not display female charts als u astrologisch gender onderzoek wilt doen. Daarnaast kunt u selecteren op kaarten van het het Noordelijk of Zuidelijk halfrond, omdat die een groot effect hebben op de gevonden huizen.
Daarna klikt u op Select Categories. Het Select Categories venster wordt zichtbaar. In het Search a category veld typt u adhd en Enter. De categorie Diagnoses: Psychological: ADHD verschijnt. U selecteert het met de muis, klikt op de rechter muisknop en selecteert Add.
Onder de juiste Tkinter bibliotheken wordt het gekozen item daarna rood gekleurd. Maar als u onder een andere versie werkt, zou u onderaan het venster Selected = 1 kunnen zien ook al blijft uw selectie zwart. Dan zit u ook goed en kunt u op Apply (toepassen) klikken.
Voor de Rodden Rating (Select) vinken we AA tot en met de B tijden aan. Dat zijn min of meer betrouwbare tijden en met de A en B erbij hopen we op voldoende gevallen (n) voor een betrouwbaar statistisch onderzoek. Daarna klikt u weer op Apply.
Met
de knop Display Records laten we de selectie zien. U kunt er
een lijst van aanmaken met Export / Links: links.txt.
Maar voor de gebruikte database (adb_export_200814_1910.xml van 14
augustus 2020) zijn dat slechts 19 personen uit een database van wel
54.000 personen. En dat is veel te weinig voor een ziekte die volgens
de Nederlandse Wikipedia
minimaal duizend ADB ingangen zou moeten hebben. Want 2% van 54000 is
1080.
Hebben die kinderen dan minder kans om beroemd te zijn? Dat zou best wel eens kunnen. Op school presteerden ze waarschijnlijk al minder. Maar wat meer voor de hand ligt dat ADB editors er geen oog voor hadden. De ADB editors voerden slechts wat aan hen bekende categorieën in. Maar ze namen niet de moeite om de door hen ingevoerde personen systematisch op ADB categorieën e screenen. En die Under-reporting zal zonder twijfel een belangrijke bron van bias zijn.
U maakt dan een uitdraai van ADB categorieën die niet representatief is voor de gevonden werkelijkheid. Want slechts enkele al dan niet correcte voorbeelden van ADHD worden u door ADB editors (vrijwel altijd astrologen) voorgeschoteld, terwijl de meeste gevallen niet geregistreerd werden.
Voor een wat meer gedegen onderzoek zult u de gevonden gevallen dus nog wel moeten natrekken. Komen ze overeen met wat de meeste ADHD onderzoekers zouden zeggen? Records waar discussie over mogelijk is, kunt u beter uit uw selectie laten. U kunt in het Display Records scherm rechtsklikken op de Open ADB Page link van Gerhswin, George om na te gaan of zijn drukke muziek inderdaad een aanwijzing kan zijn voor ADHD. De ADB biedt doorgaans een link naar de engelstalige Wikipedia, zodat u wat aan fact checking kunt doen vanuit objectief geachte bronnen. Maar een zoektocht op het internet (Gershwin+ADHD+ADD) levert alleen maar speculaties op. Deze ingang zou dus met een rechtsklik verwijderd moeten worden met een Remove. U kunt dit voorlopige lijstje aanmaken via a Export / Adb links.
Hoe komt u aan meer gevallen? U zou kunnen googelen naar celebrities with ADHD die niet in de lijst staan, maar wel in de ADB. Want dat is het voordeel van een database met publieke personen: Er wordt heel wat over hun privé leven verklapt. Ik vond in een half uur tijd veertien bekende ADHD-ers die niet als zodanig door Astrodienst gelabeld waren. Het zijn: Richard Branson, Mel B, Joan Rivers, Lisa Ling, Jamie Oliver, Ryan Gosling, Paris Hilton, Dave Grohl, Simone Biles, Justin Timberlake, Emma Watson, Will.I.Am, Terry Bradshaw en Johnny Depp. Totaal leverde dat n is 32 op en dat is beter dan de 19 gevallen van de ADB waarmee u eigenlijk geen statistiek kunt bedrijven.
Via het knopje Search a record by name kunt u snel nagaan of er een ADB record van iemand bestaat en met rechtsklikken Add kunt u ze aan de selectie toevoegen. Staan ze er al in dan zal Add niet werken, dus u hoeft niet bezorgd voor dubbele ingangen te zijn. U verwijdert records door er in het venster rechts op te klikken en remove te selecteren. Pas op: Klik niet op Display records want uw lijstje gewist en vervangen door de oorspronkelijke lijst van de ADB Categorie. Tegenwoordig wordt u daarvoor gewaarschuwd.
Via Export / Adb links maakt u een tekstbestand links.txt aan met URLs naar de geselecteerde ADB bestanden. Bewaar deze in een aparte map als documentatie van uw onderzoek voordat hij wordt overschreven. Deze optie onderbreekt lopende berekeningen niet, maar overschrijft wel een al bestaande links.txt. Als u klaar bent met selecteren, moet u onder Options nog een keus maken voor de gewenste orbs en het huizensysteem. Standaard is dat Placidus. Daarna klikt u onder Calculations op Find Observed Values.
Afhankelijk van de geselecteerde hoeveelheid data en de processorsnelheid wacht u seconden, minuten, uren of dagen (55.000 kaarten) op het verschijnen van de mededeling Process finished succesfully. Er is dan een rekenblad aangemaakt met de naam observed_values.xslx in een subdirectory met de naam Diagnoses \ Psychological\ ADHD \ RR_AA+A+B \ ORB_6_2_2_4_2_6_6_2_2_2_6 \ Placidus \ Human \ observed_values.xslx.
Zoals u ziet geeft de directorystructuur al aan wat er in het bestand zit. Wilt u het onderzoek herhalen met een ander huizensysteem en ruimere orbs, dan hoeft u die alleen maar onder options te veranderen. De nieuwe berekeningen komen dan in een andere map te staan en zullen de eerder aangemaakte versiers niet overschrijven.
De output.log in diezelfde map geeft ook aan wat u gedaan hebt. In dit geval heb ik de map ADHD hernoemd in ADHD_32 om te voorkomen dat hij later overschreven wordt.
We hebben veel astrologische waarden gevonden, maar we willen weten hoe bijzonder die zijn. We kunnen zien dat Zon in Ram vrij laag scoort, maar is dat nu toevallig zo in onze steekproef of is dat een trend?
|
|
Ari |
Tau |
Gem |
Can |
Leo |
Vir |
Lib |
Sco |
Sag |
Cap |
Aqu |
Pis |
Total |
|
Sun |
2 |
2 |
6 |
1 |
0 |
4 |
1 |
1 |
2 |
6 |
3 |
4 |
32 |
|
Moon |
3 |
2 |
2 |
2 |
3 |
4 |
1 |
1 |
5 |
6 |
2 |
1 |
32 |
|
Cusp 1 |
1 |
0 |
1 |
3 |
8 |
4 |
3 |
2 |
3 |
5 |
0 |
2 |
32 |
De volgende stap is daarom de statistische evaluatie. Daartoe kopieren we het zojuist aangemaakte bestand observed_values.xlsx naar de map TkAstroDbMaster. Tevens plaatsen we daar een control_group.xslx bestand dat aan vergelijkbare criteria voldoet (huissysteem, orbs) als de te onderzoeken groep.
De huidige TkAstroDb gebruikersgroep maakte ter controle observed_values.xlsx bestanden aan van alle personen met Rodden Rating AA t/m C onder verschillende huizensystemen en orbs. Daartoe selecteren we met Ctrl-A alle categorieën en maken een uitdraai van alle personen die tot een ADB categorie behoren. In principe vangen we ze dan allemaal, want ADB editors moeten altijd een categorie opgeven.
Deze uitdraaien vergden soms weken tijd. Daarom deelden we de door ons berekende controle groepen onderling in de cloud. U treft ze aan in adbstats onder de map Control Group. Het zijn dus uitdraaien van de ADB waarin alle ADB categorieën aangevinkt zijn. U hoeft alleen nog maar de naam observed_values.xlsx in control_group.xslx te veranderen.
Daarna kiezen we voor Calculations/ Find Expected Values waarmee het bestand expected_values.xlsx wordt aangemaakt. Maar bedenk steeds goed wat u feitelijk doet.
De standaard methode onder Options om de verwachte waarden te berekenen is de methode Subcategory, waarbij de onderzoeksgroep (een subcategorie of een mix daarvan) een onderdeel is van de controlegroep (n=59.199) met alle leden van alle categorieën uit dezelfde database.
Expected_values.xlsx bevat in dit geval de waarden van control_group.xslx vermenigvuldigd met de n=32 van de selectie en gedeeld door n=59.199 van de adb_export_200814_1910 uitdraai van alle menselijke personen.
|
|
Ari |
Tau |
Gem |
Can |
Leo |
Vir |
Lib |
Sco |
Sag |
Cap |
Aqu |
Pis |
Total |
|
Sun |
2,74 |
2,77 |
2,76 |
2,75 |
2,75 |
2,62 |
2,63 |
2,49 |
2,44 |
2,59 |
2,66 |
2,80 |
32,00 |
|
Moon |
2,69 |
2,65 |
2,71 |
2,61 |
2,71 |
2,61 |
2,64 |
2,66 |
2,67 |
2,68 |
2,69 |
2,69 |
32,00 |
|
Cusp 1 |
1,50 |
1,86 |
2,55 |
3,23 |
3,52 |
3,44 |
3,49 |
3,39 |
3,17 |
2,45 |
1,90 |
1,50 |
32,00 |
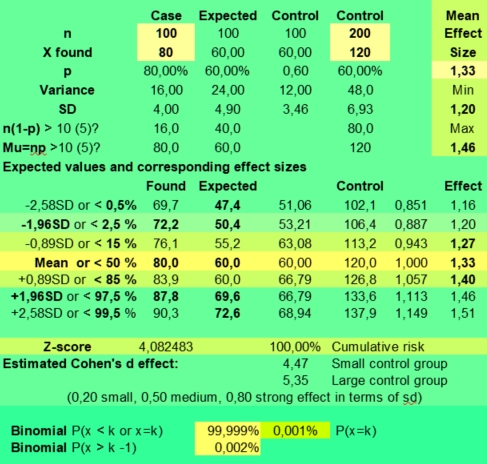
Vergelijkt u daarentegen de gevonden waarden van twee onafhankelijke (steek)groepen, bijvoorbeeld het aantal na een maand genezen personen met ziekte Z uit groep A (Case is 100, 80 herstelden) die medicatie gebruikte met de personen van groep B (Control is 100, 40 herstelden) die placebo kregen, dan is het wijs de verwachtingswaarden te berekenen uit het gemiddelde van beide groepen tezamen (n=200, 80+40=120 herstelden). Dit levert namelijk de best mogelijke schatting van de gemiddelde herstelkans op volgens de te verwerpen Nul Hypothese, die aanneemt dat het verkrijgen van het medicijn of de placebo er voor de herstelkans niet toe doet.
 Dit
is de methode independent
onder Options.
Dit
is de methode independent
onder Options.
In The calculation of the effectiveness of medication in 79 art critics ziet u een uitgewerkt rekenvoorbeeld van deze methode.
U ziet voor het medicijn een relatief klein gunstig effect van 1,33 (1,20 - 1,46), met een zeer overtuigende p-waarde van 0,00002.
ADB onderzoekers zullen in de praktijk zelden gebruik maken van deze methode, omdat zowel de onderzoeksgroep als de controlegroep relatief klein zullen zijn. De kans op statistisch significante astrologische resultaten is dan klein.
Hoe komt het dat het kleine effectgrootte van het medicijn 1,33 (1,20 - 1,46) in bovenstaand onderzoek wel zichtbaar is? Dat heeft te maken met vrijheidsgraden.
De uitkomsten van de vraag of een medicijn beter werkt dan placebo kunnen we in een kruistabel van twee maal twee zetten: Medicijn genomen of niet. Patiënt genezen of niet. Het gaat dan om (2-1)*(2-1) is slechts éen vrijheidsgraad. Maar bij astrologische vragen hebben we doorgaans te maken met 12 kolommen van case en control groepen en dus met minimaal 11 vrijheidsgraden. Er is dan veel meer variatie mogelijk en dat vermindert de kans op statistisch significante bevindingen enorm.
Kleine astrologische effecten, als ze al bestaan, worden daarom slechts statistisch aantoonbaar bij onderzoek van grote groepen. The astrological profile of 1867 ADB astrologers en het onderzoek van de 1902 schilders in Basale statistiek en kansrekening voor astrologen zijn voorbeelden hiervan. Maar op zich pleit dat niet tegen de werkzaamheid van astrologische effecten. Want kleine effecten kunnen ertoe doen als ze bij herhaling plaats vinden. Denk aan het effect van waterdruppels op een rots.
Ook het evidente effect tussen roken en longkanker werd pas na jaren grootschalig onderzoek in de vorige eeuw vastgesteld. Maar evenals het evidente statistische verband tussen de CO2 uitstoot en klimaatverandering, dat al in de jaren tachtig van de vorige eeuw werd vastgesteld, duurde het decennia voordat er echt beleid van werd gemaakt. En in beide gevallen speelden uitstekend betaalde lobbyisten van zeer winstgevende firma's een grote rol bij het verdoezelen van de gevonden feiten. Zie: De klimaatontkenners of de vele dossiers over de Tabaksindustrie en de lankmoedige overheden.
Maar goed, we doen nu aan astrologisch onderzoek. En laten we dat nu eens niet ad hoc doen. Dus zonder een beroep te doen op door astrologen bekend veronderstelde aanwijzingen en uitzonderingen op de regels. Want dat zijn nog onbewezen hypothesen. Zeg maar de astrologische bril op gevonden feiten die nimmer statistisch werden aangetoond. En wat is dan de waarde van zo'n bril? Ziet u er echt scherper mee?
Laten we daarom maar eens gewoon de statistisch gevonden feiten voor zichzelf spreken volgens het principe meten is weten. Hoe doet u dat?
Draai: Calculations / Find Chi-Square values. Het bestand chi-square.xlsx wordt aangemaakt. Dit bestand geeft aan welke planeten en huizen de meeste variatie vertoonden. Planeten en huizen die hier hoog scoren, zijn statistisch gezien het meest relevant voor een bepaalde categorie.
Gelukkig worden er geen bestanden meer gewist zoals dat in eerdere versies van TkDbAstro gebeurde.
De volgende stap is Calculations / Find Effect Size values waarmee effect-size.xlsx wordt aangemaakt. Hoeveel vaker dan verwacht komt een astrologische parameter als planeet in teken voor in een bepaalde ADB categorie?
Met Calculations / Find Cohens D Effect Size values maakt u cohens_d_effect.xlsx aan. Dit is een belangrijke maat voor de effect grootte die ook met de te verwachten variantie rekening houdt. Maar in het gebruikelijke kleinschalige astrologische onderzoek, wordt daar nog veel te weinig rekening mee gehouden.
Daarna draait u Calculations / Find Binomial Limit Values om een idee te krijgen van de p-waarden (binomial_limit.xlsx). De laatste berekening kan enige tijd duren, dus breek die niet te snel af. Een gevonden p-waarde nabij de 0, vergroot de kans dat u iets met de gevonden effect waarde voorspellen kunt. Maar een p-waarde nabij de 50% voorspelt eerder 100% willekeur.
Een gevonden effect-waarde van 6 tegen 1/6 verwacht mag op zich indrukwekkend lijken, zoals het aantreffen van een rake zes na onze eerste worp met een dobbelsteen. Zes maal zo vaak als mocht worden verwacht, maar de binomiale p-waarde van de uitkomst is maar 1/6 en de kans op een alternatieve uitkomst is 5/6. Zegt dat ons iets over deze dobbelsteen of over onze horoscoop? Dat is dan maar weer de vraag. Hoe zou u een correcte uitkomst bij voorbaat definiëren? Om te achterhalen of die zes op toeval berust of niet, moet u volgens wiskundigen en statistici beslist veel meer worpen doen.
 De
resultaten van ons kleinschalig onderzoek kunt u op het internet
bekijken in de map ADHD_32.
Het verrassende is dat Zon in Steenbok (2,31 maal zo vaak) en
Tweelingen (2,17 maal zo vaak) het vaakst voorkwamen (6 ) met
p-waarden van respectievelijk 0,0411 en 0,0533.
De
resultaten van ons kleinschalig onderzoek kunt u op het internet
bekijken in de map ADHD_32.
Het verrassende is dat Zon in Steenbok (2,31 maal zo vaak) en
Tweelingen (2,17 maal zo vaak) het vaakst voorkwamen (6 ) met
p-waarden van respectievelijk 0,0411 en 0,0533.
Ascendent in Leeuw deed het ook goed (2,27 zo vaak) met een p-waarde van 0,0200. Zon In Leeuw scoorde daarentegen het laagst met 0 gevonden tegen 2,75 gevallen verwacht (p is 0,0566).
De hoogste score vonden we voor Neptunus in Boogschutter (15, effect size 5,36, p is zeer klein) en Pluto in Libra (14, effect size 6,72, p is minimaal). Maar dat bevreemdt ons niet omdat de diagnose ADHD eigenlijk pas in de tweede helft van de vorige eeuw opkwam.
De Chi-square waarden waren niet indrukwekkend met een uitzondering voor Pluto in de huizen (21,50 bij df is 11). Pluto in H3 scoorde het hoogst: 3,44 maal zo vaak, met een p-waarde van 0,017. En dat is wel weer een interessant resultaat, want had het derde huis niet iets te maken met leren? En een Pluto in dat derde huis kan er wel en voor zorgen dat u die nogal wiedes kennis heel anders ziet.
Het spreekt vanzelf dat een groter aantal personen met ADHD noodzakelijk is om enig serieus statistisch onderzoek met deze database te kunnen doen. Want waarden van 0 tot 6 zijn door toeval te verwachten in bijna 95% van de gevallen bij een p van 1/12 en n is 32. Effectgroottes tussen de 0 en 2,63 zouden dan niet zo indrukwekkend zijn. Alleen waarden van 8 (3 maal vaker dan verwacht) en hoger zouden met een kans van 0,40% (p = 0,004) statistisch significant zijn.
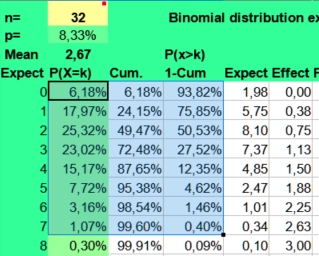
U kunt de Binomial_distribution_for_astrology.ods gebruiken om na te gaan, hoe groot uw onderzoeksgroep moet zijn om toch wel flinke effecten als 2 maal zo vaak of 2 maal zo weinig aan te tonen. Dat doet u door met de waarde n to spelen
Maar vrijwel alle speculaties op het internet over ADHD + astrology zitten ernaast. En dat komt omdat deze astrologen niet in statistische feiten geïnteresseerd zijn, maar zich liever van het hen vertrouwde astrologisch symbolisme wilden bedienen. Zie ook: Dale Huckeby: After Symbolism:
Sjoerd Visser (2020/22)