|
De grootte van de JFS cache instellen |
De eComstation standaard waarden Wat zijn de beste JFS cache waarden?
|
Toen OS/2 versie 2.0 (1992) uitkwam was het zijn tijd ver vooruit. Het bevatte een visionaire object georiënteerde shell en het voor servers ontworpen "high performance" bestandssysteem HPFS. De PC's van die tijd beschikten echter maar over weinig schijfruimte en geheugen. Van de vele gigabytes die het High Performance File System aankon kon men slechts dromen. Ook voor OS/2 Warp 3 (1994) en OS/2 Warp 4 (Merlin, 1996) clients was de 2 gigabyte HPFS cache en bestandsgrootte van HPFS meer dan voldoende, maar een paar jaar later al niet meer.
Eind jaren negentig waren de Personal Computers zo krachtig dat ze gemakkelijk voor multimedia en servertaken konden worden ingezet. Met NT uitgeruste PC's vervingen UNIX werkstations en servers. Later kwamen daar Linux servers bij. IBM had de strijd om de PC Desktop met Microsoft al opgegeven, maar gaf zijn laatste OS/2 Warp Server for e-Business (1999) nog wel het van AIX afkomstige Journaled File Systeem (JFS) mee. Dit ook om haar zakelijke OS/2 klanten minder afhankelijk te laten zijn van de prijzige licenties op Microsofts HPFS386 bestandssysteem.
Alle versies van eComstation komen met JFS. De versies 1.0, 1.1 en 1.2 booten van HPFS, FAT of van CD via een RAM-disk, maar nog niet van JFS. eComStation 2.0 ( en nu al de bèta versies ervan) zal ook van JFS kunnen booten.
Een Logical Volume Manager (LVM) is een software laag die meerdere partities van vaste en soms verwisselbare schijven aan elkaar kan rijgen tot een geheel op maat.
Het concept stamt van het Virtual File System (VFS) van Linux en Unix waar u met de file system tabel (fstab) partities aan mappen op het root filesystem koppelt.
/dev/hda4 /usr reiserfs acl,user_xattr 1 2 /dev/hda6 /mnt/data hpfs user,gid=100,uid=500,umask=022 1 2
Maar als ik de data partitie /mnt/data uit zou willen uitbreiden met een grotere partitie op een andere schijf (zeg /dev/hdb5), dan lukt dat niet. Want partities zijn onder OS/2 en Windows aan één schijfletter en onder Linux aan één directory op het root bestandssysteem gekoppeld. En HPFS staat i.t.t. NTFS dergelijke uitbreidingen niet toe.
Ik kan onder Linux hoogstens de nieuwe partitie als /data1 mounten, de inhoud van /data naar /data1 kopieren, vervolgens umount /mnt/data uitvoeren en partitie hdb1 daarna als /mnt/data mounten.
/dev/hdb1 /mnt/data hpfs user,gid=100,uid=500,umask=022 1 2
En daarmee is Linux flexibeler dan het OS/2 van voor de intrede van LVM, waar de schijf /dev/hdb1 waarschijnlijk als de legacy schijf D: (de eerste primaire partitie op de 2e vaste schijf) zal verschijnen en uw hele schijvenstelsel in de war kon schoppen. Om die reden maakte ik op 2e en 3e vaste schijven bij voorkeur logische partities aan: ze kregen drive letters aansloten bij andere logische partities. Zie: Over partities en partitioneren.
 Maar
met de komst van de Logical Volume Manager (LVM) van IBM's OS/2 4.5
zou deze oefening een fluitje van een cent zijn. Althans wat
eComStation betreft. De OS/2 LVM kan iedere partitie een door u
gewenste unieke schijfletter geven en voorkomt daarmee ook dat eerder
toebedeelde schijfletters door het nieuw aanmaken of wissen van
partities in positie opschuiven. Sterker nog: u moet de nieuwe
schijven eerst in LVM aanmelden voordat u ze kunt zien.
Maar
met de komst van de Logical Volume Manager (LVM) van IBM's OS/2 4.5
zou deze oefening een fluitje van een cent zijn. Althans wat
eComStation betreft. De OS/2 LVM kan iedere partitie een door u
gewenste unieke schijfletter geven en voorkomt daarmee ook dat eerder
toebedeelde schijfletters door het nieuw aanmaken of wissen van
partities in positie opschuiven. Sterker nog: u moet de nieuwe
schijven eerst in LVM aanmelden voordat u ze kunt zien.
De OS/2 LVM van IBM kan meer: Als de oude datapartitie op JFS zou staan, dan zou u hem onder OS/2 gewoon met de nieuwe partitie kunnen uitbreiden. Zonder een reboot. Zie: Logical Volume Manager.
Doorgaans zijn dergelijke hoogstaandjes zowel aan een bepaalde LVM als een bepaald bestandssysteem gekoppeld. Onder Windows NT werkt het alleen met NTFS. Maar een Linux driver voor NTFS kan nu niet meer op de betrouwbaarheid van de fstab rekenen. En als u het onder OS/2 met JFS doet, vraag ik me af of een Linux LVM daarvan op de hoogte wordt gesteld. Waarschijnlijk niet. Ik heb het niet uitgetest, want ik vreesde voor mijn data.
De clou is: doorgaans kent een logische volumebeheerder alleen de logica van zijn eigen besturingssysteem. DOS en Windows vereisen een primaire C partitie om te booten. OS/2 paste zich aan een boot dus ook van andere schijfletters. Maar wel als de OS/2 bootmanager op één van de drie of vier mogelijke primaire partities staat. Maar Linux werkt niet met schijfletters. De voor Linux uitgebrachte logische volumebeheerders zijn dus niet compatibel met die van OS/2. Logische volumebeheerders zijn voor het beheer van vaste schijfruimte op servers bedoeld en niet voor multibootsystemen met verwisselbare media. Wat dat betreft is de aan OS/2's boot manager gekoppelde LVM wel een heel vreemde eend in de bijt.
Onder UNIX worden mappen en bestanden als een getal (inode nummer) opgeslagen. Op JFS en HPFS is dat ook het geval. Computers werken immers met getallen.
Voor de JFS cache is het dus handiger om een bestand via zijn inode nummer aan te spreken, dan met zijn lange bestandsnaam. Ook al is die bestandsnaam niet lang. Want bestandsnamen worden door de computer via codetabellen toch eerst weer naar lange binaire getallen omgezet. En vervolgens wordt gekeken welk inode nummer er bij hoort. Maar omdat u beter alfanumerieke bestandsnamen onthoudt moet JFS de door u onthouden naam eerst omzetten in een inode nummer. En directory listings (dir) als alfanumerieke bestandsnamen retourneren.
Hoe weet u het inode nummmer van een bestand?
Een gangbare methode is het gebruik van het gebruik van het utility ls uit het unixos2 project. Ls- i [naam] geeft de inode nummer van een bestand of directory.
[Q:\mpg]ls -i i:\unixos2\bin\ls.exe 18321646164142662402 i:\unixos2\bin\ls.exe
Een ander optie is het gebruik van JFS herstelprogramma jrescuer.
De opdracht jrescuer x: /d > f:\Inodes_X.txt maakt een lijst van inodes van JFS schijf X aan.
x: Jrescuer Aggregate Block Size: 4096 Offset to inode table: 11325440 Log size for it: 12 Total blocks 179567328 ------------------------------- 2 .. 32 VirtualBox DIR ------------------------------- 2 .. 33 compreg.dat 64 Machines DIR ------------------------------- 32 .. 4 Ubuntu DIR
Dergelijke lijsten kunnen tientallen megabytes lang worden. Waarom zou u ze met jrescuer aanmaken? De reden is dat als u een bestand wist, de bestandsnaam uit de directory ingang wordt gehaald. Tevens wordt de inode vrijgeven, maar omdat er zoveel inodes op een volume staan blijft de vrij gegeven inode nog wel even vrij. Als u het gewiste bestand met jrescuer (of June) terug wilt halen, scant jrescuer de schijf op vrijgegeven inodes die nog naar oude data verwijzen. Als het gewiste bestand over een lange bestandsnaam in de Uitgebreide Attributen beschikte, kan JUNE die weergeven. Maar anders krijgen de gewiste bestanden een aan de hand van het inode # gegenereerde bestandsnaam, bijv. I0000016.RCN voor inode 16.
Het aantal inodes op een schijf is een vast gegeven. De inodes worden tijdens het formatteren in groten getale over de schijf verdeeld. In theorie kan een schijf met veel kleine bestanden een tekort aan inodes krijgen. U zou dan geen nieuwe bestanden meer kunnen aanmaken. Maar dat komt zelden voor.
Bij het formatteren van JFS worden relatief weinig structuren aangemaakt. Het gaat om de XX kilobyte voor gebruik door het systeem. Het formatteren gaat dan ook snel. De belangrijkste parameter naast /FS:JFS is de blokgrootte in Bytes. De standaard JFS blokgrootte is 4096 bytes. De alternatieve kleinere waarden zijn 512, 1024 en 2048 bytes. Bij kleinere waarden worden er meer inodes aangemaakt en wordt de schijfruimte aanzienlijk efficiënter gebruikt voor kleine bestanden.
format k: /fs:jfs /bs:1024.
Maar in de regel voldoet de standaard blokgrootte van 4096 bytes (4 KiB) het best, omdat 4 KiB ook de grootte van een PageFrame en een JFS cache buffer is. De kleinere blokgroottes verspillen minder schijfruimte op partities met veel kleine bestanden, maar geven ook meer kans op fragmentatie van de grotere bestanden.
|
Slack |
De gemiddelde verspilling per bestand (slack) is de helft van de blokgrootte. Zo bevat mijn map decoded van Pronews 1603 bestanden met een totale grootte van 51,5 MB. Veel bestanden zijn doublures en klein (vcf bestanden). Bij een blokgrootte van 4 KiB levert dat 1603*2 KiB = 3206 KiB slack op (3,13 MiB oftewel 6,1% van 51,5). Maar bij een blokgrootte van 1024 bytes zou dat nog maar 1,5% zijn. De verspilling van een hele schijf is op JFS wat lastig te berekenen. Dit is de uitvoer van chkdsk op een schijf met vooral programmabestanden (zonder /f): 43005972 kilobyte totale schijfruimte
8467 kilobyte in 4086 directory's.
27471647 kilobyte in 49191 gebruikersbestanden.
16000 kilobyte voor uitgebreide kenmerken.
65956 kilobyte voor gebruik door het systeem.
15460836 kilobyte beschikbaar voor gebruik.Als u alleen uitgaat van "27471647 kilobyte in 49191 gebruikersbestanden" betekent dat bij een blokgrootte van 4 KiB dat de slack (2 *49191*100) / 27471647 of 0,36 % is. De 4086 directories zouden gemiddeld 4086*2 KiB verspillen. En ook de uitgebreide kenmerken worden in aparte blokken opgeslagen. Blijkbaar zijn hier u 16000/4 blokken voor in gebruik. Zie Clustergrootte voor meer details. |
Bij het formatteren wordt eerst het zogenaamde superblock aangemaakt. Deze bevat de meest basale informatie over het bestandssysteem: het type en het versienummer van het bestandssysteem, de grootte van het bestandssysteem, de blok- en allocation groep grootte, eventuele ondersteuning voor sparse objecten, de status waarin het bestandssysteem afgesloten werd (clean, dirty) en meer.
Het superblock bevat de essentiele informatie die een chkdsk en dfsee het eerst zullen nagaan. Ter controle zijn er eerder gemaakte kopieën van beschikbaar. Aan de hand van het logbestand kan de laatste stand van zaken volgens het logbestand meestal snel worden gereconstrueerd.
Maar het is wel belangrijk om te weten dat het logbestand alleen de voltooide transacties in de administratie logt en dus niet de door u (of door de lazy write JFS cache nog niet) tijdens de crash (zeg een stroomstoring) opgeslagen gegevens. Laat staan de gegevens die u met Ctr-S nog niet opgeslagen hebt, want die zaten toen nog niet in de buffers van JFS cache maar elders in het vluchtige RAM. Een chkdsk herstelt dus slechts de laatst bekende stabiele situatie. En die is afhankelijk van uw omstandigheden (JFS synctime en uw gebruik van Ctrl-S).
Het doel van een loggend bestandssysteem is om de integriteit van het bestandssysteem te handhaven. Daarom worden de veranderingen in de de metadata als transacties gelogd. Een bestand of map is veranderd of niet. Een voltooide transactie is voor chkdsk een feit zodra het door de serieel de transacties naar het logbestand schrijvende lazy write Lcache volledig in het logbestand op de schijf is geschreven.
Voor details over superblock foutmeldingen van chkdsk: Zie fsckmsge.h in de broncode.
Alle bestandskenmerken worden opgeslagen in inodes. De inode zelf wordt door een uniek getal (inode #) gekarakteriseerd. Andere bestandskenmerken zijn bijv. het bestandstype (bestand, directory, link), de tijd van aanmaak (ctime), laatste verandering (mtime) en meest recente toegang (atime), de toegangsrechten (uid, gid), het gebruikte aantal blokken en de grootte van het bestand.
Ook het al dan niet hebben van uitgebreide attributen en het aantal (hard) links (verwijzingen) valt hieronder. Een inode met 0 links is vrij, maar een inode met 2 links verwijst naar een bestand dat 2 keer voorkomt in hetzelfde bestandssysteem. Voor details zie jfs_dinode.h.
Overigens suggereert een ls -ila op de rootschijf aan dat de DOS attributen hier niet onder vallen. De UNIX POSIX standaard kent ze niet en regelt dit via de eigenaar (onder OS/2 root).
18127821512059269247 drwxrwxrwx 1 0 0 0 2009-03-09 21:44 OS2 17865964236292030289 -rw-rw-rw- 1 0 0 60137 2007-10-18 23:01 OS2BOOT
Bestandsnamen en directorynamen worden samen met hun inode nummer in de inode van hun directory opgeslagen. De inode van een directory fungeert dus als een soort hostbestand. Passen ze hier niet in dan wordt een soort aanhangsel (directory map) gebruikt.
De omzetting van bestandsnamen in inode nummers wordt gecached door de directory name lookup cache (dnlc) in de JFS.IFS driver. Erg lange bestandsnamen worden niet gecached om vervuiling van de cache te voorkomen.
I-nodes met metadata en bijbehorende data blokken met de bestandsinhoud zijn georganiseerd allocatie groepen. Hierdoor zijn data en metadata net als op HPFS in elkaars nabijheid te vinden en dus sneller in te lezen. Maar natuurlijk wordt altijd eerst de cache geraadpleegd.
Dit is dus een andere opzet dan bij de centrale File Allocation Tabel van FAT die aan het begin van de partitie staat. Om een bestand op FAT te vinden moet het systeem eerst de ongesorteerde FAT tabel raadplegen. En als het bestand onderin de tabel staat duurt dat zonder cache erg lang. HPFS en JFS maken daarentegen gebruik van een gesorteerde B (+) tree algoritmen, die meer werken op de manier waarop u een telefoonboek doorzoekt. U begint niet bij A als u meneer K zoekt. FAT zou dit wel doen, maar daar kan A weer achteraan staan. Want de FAT (klad)tabel is ongesorteerd.
Bestanden, bestandsnamen en mappen worden door uw computer als binaire reeksen van enen en nullen (binaire getallen) gecodeerd. De beschikbare tekens (characters) worden door uw actieve tekenset (codepage) bepaald. Op het scherm worden de tekens door grafische fonts weergegeven. Maar de tekens worden door de computer als reeksen van nullen en enen verwerkt en opgeslagen. De computer werkt immers digitaal. De per bestand gebruikte versleuteling- en decodeertechniek is dus van groot belang.
Met de onderstaande CONFIG.SYS instelling worden de door u op het binair werkende toetsenbord ingevoerde tekens standaard volgens de 256 tekens bevattende 8 bits of 1 byte (2^8=256 is 256 combinaties van enen en nullen) codepage nummer 850 (Multilingual Latin 1 character set) tekenset geïnterpreteerd.
CODEPAGE=850,437
Als u het onder codepage 850 van DOS en OS/2 weer inleest ziet het er perfect uit. Maar als u het onder Windows ANSI (CP 1252) inleest, zien de 128 speciale tekens er vaak anders uit. Zie hiernaast. En een Japanner zou geheimtaal zien. Zie voor dit probleem ook: Codetabellen en speciale tekens.
Ieder bestandssysteem kan dus bestanden bevatten die onder verschillende talen (tekensets) zijn aangemaakt. Want degene die het bestand aanmaakt hoeft niet dezelfde codepage actief te hebben als u. De vraag is nu hoe een tekstverwerker of browser kan weten onder welke tekenset (codepage) een bestand opgeslagen werd? Hoe moet hij ieder getal moet interpreteren.
Het antwoord is: Hij weet het niet. Want de gebruikte tekenset is niet het bestandssysteem terug te vinden. En ook niet in een plat tekstbestand. Alleen tekstverwerkers als OpenOffice kunnen het als metadata (opmaak, fonttype) aan hun eigen bestandstypen meegeven. Ook in HTML kan de tekenset als een tag meegegeven worden, zodat uw browser de over het internet verzonden reeksen van enen en nullen juist interpreteren kan. Gelukkig maar, want het internet bestaat uit heel veel talen en besturingssystemen. Niet alleen uit het eigenzinnige Windows ANSI. Om die reden werden de grafische printerformaten (ps, pdf) ook populair. Maar die slaan uw informatie in veel grotere bestanden op.
Om dit lastige probleem te voorkomen slaat JFS zijn gegevens in Unicode (UTF-8) op. Deze tekenset biedt elk teken een uniek getal ongeacht de gebruikte taal. Dus JFS vertaalt uw 8 bits per teken invoer (CP 850 of wat maar actief) naar een van uw landsinstelling onafhankelijke tekenset.
Maar dat geeft wel wat meer overhead. Het slim ontworpen Unicode systeem gebruikt 1-4 bytes per teken. De meest voorkomende 128 ANSI tekens worden net als onder CP 850 als 1 byte gecodeerd (klassiek ANSI is trouwens 7 bits), maar voor de 128 per land vaak verschillende speciale tekens (de 8e bit) en niet te vergeten de vele aparte tekens van de oosterse talen (Chinees, Japans, Koreaans) zijn veel meer bits nodig.
Op het universele 1-4 bytes per teken UTF-8 gebruikende JFS zal een in 1 byte per teken onder gecodeerd CP 850 bestand met speciale tekens dus meer ruimte innemen. Maar uw bestandsbeheerder laat dit niet zien. Die geeft alleen de grootte van het bestand in uw actieve 8 bits codepage tabel aan. Anders zouden uw OS/2 programma's niet doorhebben dat het om het zelfde bestand gaat. Alleen aan de hand van de sneller afnemende vrije ruimte op JFS zou u de daadwerkelijk door het bestand ingenomen ruimte kunnen zien. En dat is per bestandssysteem (clustergrootte, manier van opslaan EA's en systeemoverhead) weer verschillend.
Het de vele tekensets integrerende UNICODE.SYS (UTF-8, het 8-bit UCS/Unicode Transformation Format) stuurbestand moet voor de JFS.IFS, UDF.IFS en andere installeerbare stuurbestanden staan.
DEVICE=C:\OS2\BOOT\UNICODE.SYS
Stuurbestanden die van JFS geladen worden, kunnen voor de zekerheid het best na de JFS.IFS opdracht staan..
Met de volgende regel wordt het JFS stuurbestand en zijn lazy write cache in CONFIG.SYS geladen:
DEVICE=C:\OS2\BOOT\UNICODE.SYS IFS=C:\OS2\JFS.IFS
De grootte van de JFS cache is standaard 12,5 % van het fysieke geheugen tot een maximum van 64 MiB. Op een systeem met 256 MiB hoofdgeheugen levert dit een 32 MiB JFS cache op. En bij 512 MiB geheugen gebruikt de JFS cache 64 MiB systeem geheugen. Maar op dergelijke systemen heeft u waarschijnlijk vele (soms honderden) megabytes geheugen over. Daarom zou ik de cache veel groter maken. En niet een achtste, maar een kwart van het RAM aan de JFS cache geven.
Met de parameter /CACHE:128000 wordt het JFS stuurbestand expliciet met een lazy write cache van 128.000 KB cache opgestart:
IFS=C:\OS2\JFS.IFS AUTOCHECK:* /CACHE:128000
Helaas kan de maximale grootte van JFS cache buffers na het booten niet meer worden bijgesteld. Zet u de waarde te laag, dan houdt u veel onbenut geheugen over. Zet u de waarde te hoog dan nemen het vrije en /of het virtuele geheugen teveel af en kunt u in het ergste geval niet meer booten.
Bij te weinig vrij geheugen zullen programma's als VPC en VirtualBox geen geheugen meer kunnen reserveren om gastbesturingssystemen in te laden. En zullen gewone gebruikersprogramma's eerder naar de swapper.dat verplaatst worden. Kies dus een redelijk compromis waarbij u aldoor voldoende vrij geheugen over houdt om uw programma's snel te kunnen laden.
Bij honderden megabytes grote JFS caches kunnen zich problemen met de virtuele adressering voordoen. Het /CACHE geheugen dat voor het JFS bestandssysteem gereserveerd wordt, wordt in het systeemdeel van de 4 GiB 32 bits virtuele adressenruimte afgebeeld. Bij de maximale VIRTUALADDRESSLIMIT van 3092 zal dit nog maar 1024 MiB zijn. En als de helft daarvan wordt ingenomen door het videogeheugen van een 512 MIB kaart en 256 MiB door de PCI bus, dan mag u blij zijn als de overige stuurbestanden nog adressen vinden om hun buffers in te laden. Om die reden (gebrek aan virtuele adresruimte) lukte het me niet om caches groter dan 800 MiB te laden. Meestal werd een te grote cache gerest op de 64 MiB defaultwaarde. En soms startte PM niet op.
Probeer daarom een grote JFS cache (zeg 500 MiB of meer) eerst met een VIRTUALADDRESSLIMIT (VAL) van 2048 of minder uit. Als een JFS.IFS /CACHE:500000 volgens cachejfs slechts met de 64 MiB default waarde laadt, verlaag dan de waarde van JFS of de VAL. Dat geldt natuurlijk ook voor andere grote caches en buffers (zeg > 128 MiB HPFS386 cache) die virtuele adressen met de cache delen.
SNAP gebruikers kunnen het aan het videogeheugen toegewezen deel van het systeemgeheugen beperken met gaoption vidmem 32 of door SET SNAP_MAXVRAM_32MB=Y in de CONFIG.SYS plaatsen. Het door SNAP gereserveerde videogeheugen van een 256 MIB RAM videokaart (standaard: alles!) zal dan van 256 MIB naar 32 MiB gaan, maar voor eCS met zijn 2D applicaties maakt dat niets uit. Dat is wel logisch, want zelfs een 22" LCD monitor in een 1680 maal 1050 resolutie met 16M kleurendiepte (24 bit truecolor) heeft maar 6 MiB videoram nodig. Of bij double buffering 12 MiB videoram. De rest is beschikbaar voor 3D effecten, die OS/2 applicaties niet benutten. Daarom zou gaoption vidmem 13 het ook prima moeten doen. De honderden megabytes virtuele adresruimte die na een reboot vrij komt kunt u beter aan voor OS/2 nuttiger zaken als caches (JFS, HFS386) en wel benutte buffers (video, audio) besteden.
Vertraagd doorvoeren (lazy write) staat standaard ingeschakeld. Dit voorkomt dat iedere kleine bestandswijziging op JFS meteen naar de schijf wordt geschreven. Het doorvoeren van de veranderde data in de JFS cache buffers naar de blokken van het JFS bestandssysteem gebeurt dan niet meteen (asynchroon), maar bij voorkeur op gezette tijden (synchroon).
#define MIN_RAPAGE 2 /* minmum number of read-ahead pages */
#define MAX_RAPAGE 8 /* maximum number of read-ahead pages */
#define CM_WRCLNBLKS 8 /* write behind cluster size */
Cachejfs zonder parameters geeft de huidige situatie weer: links met lazy write (synchrone doorvoer) en rechts na het uitschakelen van vertraagd doorvoeren (asynchrone doorvoer).
[F:\]cachejfs
SyncTime: 64 seconds
MaxAge: 256 seconds
BufferIdle: 8 seconds
Cache Size: 128000 kbytes
Min Free buffers: 640 ( 2560 K)
Max Free buffers: 1280 ( 5120 K)
Lazy Write is enabled
|
[F:\]cachejfs /lw:off
SyncTime: 1 seconds
MaxAge: 0 seconds
BufferIdle: 0 seconds
Cache Size: 128000 kbytes
Min Free buffers: 640 ( 2560 K)
Max Free buffers: 1280 ( 5120 K)
Lazy Write is disabled
|
Hoe moet u de uitvoer van cachejfs interpreteren?
Het synchronisatie-interval SyncTime is het aantal seconden dat de cache maximaal afwacht voordat het zijn synchronisatiedraad start.
Voor de synchronisatie van veranderde cachegegevens (buffers) met de vaste schijf kiezen de meeste caches bij voorkeur een rustig moment op waarin de vaste schijf niet aan het werk is. Zo kent de HPFS cache de parameter /DISKIDLE:1000 parameter die aangeeft dat de cache de gegevens (buffers) pas naar de vaste schijf mag schrijven als die 1000 ms in rust (idle) was. Schijfactiviteiten verlopen immers in korte pieken en langere dalen. En 1 s rust wordt gezien als een dal. Een goed moment dus om achterstallig onderhoud te te plegen.
Maar bij JFS start de cache synchronisatie draad om de SyncTime seconden. Want wachten totdat de schijf rustig is, heeft minder zin op JFS volumes die meerdere schijven kunnen bevatten en op servers die aldoor in beweging zijn. Bovendien kan en moet een optimaal ingestelde 256 MiB JFS cache veel langer wachten dan een 2 MiB HPFS cache vanwege zijn grotere omvang. Zo'n grote JFS cache kan langer wachten, omdat hij over veel meer vrije of snel vrij te maken buffers beschikt dan een 2 MiB HPFS cache. Vrije buffers zijn nodig voor het snel kunnen inlezen en schrijven van nieuwe data. Maar een optimaal ingestelde 256 MiB JFS cache moet wel langer wachten met synchroniseren omdat zijn cache overhead veel groter is. Want als zo'n grote cache synchroniseert moet het veel meer buffers op hun status beoordelen.
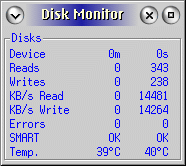
Een voorbeeld: Terwijl ik dit schrijf converteert ffmpeg een MPEG2 bestand op JFS partitie met een 512 MiB JFS cache naar AVI en geeft Disk Monitor aan dat er 428 KBS gelezen en 65 KBS geschreven wordt. Het avi bestand zal dus 6,5 zo maal klein zijn dan het MPEG2 bestand. Althans wat dit filmdeel betreft.
Stel dat een 1 MiB cache dit proces moest cachen. De cache is dan met een 428+65 = 493 KBS I/O stream in 1024/493 = 2,077 seconden gevuld. Hij moet dan wel synchroniseren. Dat wil zeggen 65* 2,077 KB is 135 KIB naar de schijf schrijven en 1024 KiB data evalueren. En dat zijn met de HPFS clustergrootte van 512 bytes 2048 blokken.
Hoe zit dat met een 256 MiB JFS cache? Deze heeft 1024*256/4 is 65536 4 KiB blokken per ronde om te evalueren. Dat zijn er dus 32 zoveel (64 maal zoveel voor mijn actuele 512 MiB JFS cache). Maar hij heeft ook veel meer capaciteit. Stel dat een derde hiervan vlot beschikbaar is (87381 KiB). Dan duurt het 177 seconden voordat de dynamische buffers gevuld zijn. Wat FFMPEG betreft zou een synctime van 120 seconden prima voldoen.
 Maar
nu ga ik ook dezelfde MPEG2 film kopieren.
Maar
nu ga ik ook dezelfde MPEG2 film kopieren.
Disk Monitor geeft op een zeker moment het volgende aan: 14481 KBS read en 14264 KBS write. Maar ik zie later veel lagere waarden. Wees er dan op bedacht dat de data worden gecached. Of dat de cache veel overhead heeft .
Cstats gaft bij de overgang van 14 MBS naar 4-5 MBS het volgende aan.
[F:\]cstats cachesize 125000 cbufs_protected 10040 hashsize 65536 cbufs_probationary 58 nfreecbufs 113681 cbufs_inuse 0 minfree 10000 cbufs_io 0 maxfree 20000 jbufs_protected 1199 numiolru 0 jbufs_probationary 13 slrun 11239 jbufs_inuse 0 slruN 83332 jbufs_io 0 Other 9 jbufs_nohomeok 0 [F:\]cstats cachesize 125000 cbufs_protected 83289 hashsize 65536 cbufs_probationary 28453 nfreecbufs 13178 cbufs_inuse 0 minfree 10000 cbufs_io 0 maxfree 20000 jbufs_protected 43 numiolru 0 jbufs_probationary 27 slrun 83332 jbufs_inuse 0 slruN 83332 jbufs_io 0 Other 8 jbufs_nohomeok 2 ohomeok 2
In korte tijd nemen de cbufs_protected enorm toe. Dit is een geval van protected cache poisining. Nee. Bij copy A B wordt a 2 x geteld!!
De cache bekijkt tijdens zo'n synchronisatiedraad allereerst of de buffers gewijzigde data bevatten. Buffers die niet al te recent (> BufferIdle seconden) beschreven zijn, worden naar de vaste schijf geschreven, en de oudste onbeschreven of al eerder bijgewerkte buffers worden vrijgemaakt totdat Max Free vrije buffers is bereikt.
Deze vrije buffers worden gebruikt bij het (read ahead) inlezen van bestanden en bij het schrijven van nieuwe bestanden. In het begin, bij de initialisatie van de cache zijn alle buffers nog vrij, maar na enige tijd zullen de vrije buffers van een relatief kleine JFS cache standaard nog maar tussen de 2% (Min Free buffers) en 4% (Max Free buffers) van de cache grootte schommelen.
Maar als de cache door aanhoudende I/O niet meer over een minimaal aantal vrije buffers (Min Free buffers) beschikt, zal de synchronisatiedraad eerder moeten worden opgestart.
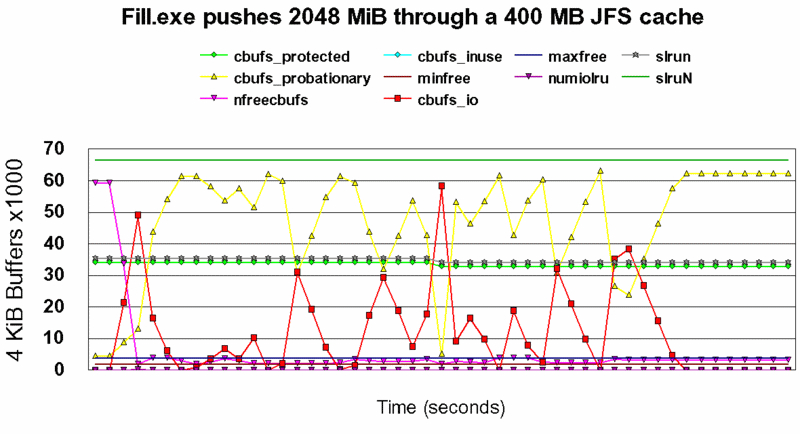
Die situatie deed zich voor tijdens onderstaande fill test, waarbij het programma fill in korte tijd grote bestanden aanmaakt:
[K:\test]FILL k:\test\test6 2047 Writing file k:\test\test6 of size 2047 MB. Time elapsed : 65 seconds. [K:\test]FILL k:\test\test7 4096 Writing file k:\test\test7 of size 4096 MB. Time elapsed : 120 seconds.
Het aantal vrije buffers (nfreecbufs 2445) in deze 500000 KB grote LW JFS cache werd zelfs minder dan minfree (2500) vanwege het grote aantal door fill.exe beschreven buffers (cbufs_probationary 100576).
[F:\]cstats cachesize 125000 cbufs_protected 11074 hashsize 65536 cbufs_probationary 100576 nfreecbufs 2445 cbufs_inuse 0 minfree 2500 cbufs_io 9176 maxfree 5000 jbufs_protected 1721 numiolru 248 jbufs_probationary 0 slrun 12795 jbufs_inuse 0 slruN 83332 jbufs_io 0 Other 7 jbufs_nohomeok 1
Op zo'n moment moet de cache orde op zaken stellen en wordt gedurende SyncTime slapende synchronisatiedraad eerder geactiveerd.
Wat gebeurt er tijdens zo'n synchronisatieronde?
De cache zoekt naar recente veranderingen in de door bestanden en metadata gebruikte buffers en zal de oudste niet of niet recent beschreven of opnieuw ingelezen gelezen buffers als eerste vrijgeven. Want die bevatten gegevens die er volgens de primitieve maar snel werkende logica van de cache algoritmen nu minder toe doen.
Maar als de JFS cache een simpel Least Recently Used (LRU) uitwerpmechanisme had, oftewel het First in First out (FIFO) algoritme zou hanteren, betekent dit dat als u met Mplayer eenmalig een film op JFS afspeelt, het MPG-bestand alle eerder veelvuldig benaderde bestanden en directories in korte tijd uit de cache zou gooien, ten behoeve van de recent ingelezen bestandsfragmenten van de film. Want dat behelst First in, first out. Zo'n film zal in no time alle vrije buffers opmaken. En vervolgens de oudste plaatsen in een FIFO cache opeisen omdat het in het tempo waarin hij (zeg 4 MiB/s bitrate) nieuwe vrije buffers nodig heeft.
De JFS cache kan vooraf niet weten of u dit door mplayer ingelezen MPG bestand vandaag maar eenmaal zult zien of dat u aan (onder OS/2 onwaarschijnlijk) MPEG editing doet. Maar de makers van caches weten wel dat de situatie van een het grote maar eenmaal ingelezen bestand zich relatief vaak voordoet. Daarom cachet de WWW proxy squid objects niet boven een bepaalde grootte (object_size 4096 KB). En koos HPFS voor een 64 KiB limiet. Hoe lost de JFS cache dit op. Want deze zou in principe ook heel grote database bestanden moeten kunnen bufferen. Die bovendien over meerdere vaste schijven verspreid kunnen zijn.
Om te voorkomen dat in het nabije verleden herhaald gebruikte buffers door nog recentere maar slechts eenmalig gebruikte buffers in de JFS cache vervangen worden, maakt de cache niet alleen onderscheid tussen vrije en bezette buffers, maar ook een onderscheid tussen de aard van de al bezette buffers.
Het vrijgeven van een niet gebruikte en niet veranderde probationary buffer is simpel. Je werpt hem gewoon uit de cachetabellen en markeert hem als vrije buffer. Maar als een buffer beschreven (dirty) is, dan moet de bufferinhoud eerst met de schijf gesynchroniseerd worden (flushing). Pas als dat gebeurd is kan hij eventueel vrijgegeven worden.
|
De CPU-use van JFS transacties |
Dit synchroniseren van de cache wordt in kernel space (ring 1) gedaan. De CPU use die hiermee gemoeid is kunt u niet met top of CPU monitor gadeslaan. Alle user space programma's die in ring 3 draaien geven alleen maar het CPU gebruik van gebruikersprogramma's weer en kunnen de system overhead in ring 1 slechts indirect meten. Zo meet diskio de snelheid waarmee een bepaalde cpu-intensieve recursieve draad uitgevoerd wordt zowel voor en tijdens de schijfacties. Als de draad in ring 3 tijdens de gemeten disk IO tweemaal zo langzaam uitgevoerd wordt, leidt diskio daar indirect 50% (of iets minder) system overhead uit af. Maar als een grote JFS cache gedwongen wordt om zeg 100 MiB aan 'oude' gegevens, versneld naar niet contigue plaatsen op de schijf weg te schrijven, bijvoorbeeld doordat een benchmark programma de vrije (zeg 20 MiB) buffers van de lazy write cache ineens met 120 MiB nieuwe random op JFS geplaatste gegevens vult, lijkt het alsof het systeem bevriest. De CPU monitor van XWorkplace zal dan stil staan. En ook Watchcat en CAD handler werken niet. U hoort zelfs geen biepjes meer. Is OS/2 dan vastgelopen? Nee. Wacht dan gewoon een paar minuten af. Ook als het LED lampje van de vaste schijf nog nauwelijks lijkt te werken. Als de kernel in ring 1 zijn dringende niet door gebruikersprogramma's in ring 3 onderbroken zaken op JFS geregeld heeft, komt er weer CPU tijd vrij voor de pre-emptive onderbroken (nu even alle!) gebruikersprogramma's en zullen Watchcat en CAD handler alsnog verschijnen. |
Het als vrij markeren van de oude al afgespeelde buffers van een MPG film is dus een fluitje van een cent. Ze zijn niet veranderd. Ze worden dus vliegensvlug uit de cachetabel geworpen. En de vrijgemaakte probationary buffers maken plaats voor nieuw ingelezen probationary buffers die gebruikt worden om het actuele deel van de film te bekijken.
Buffers die korter dan BufferIdle (hier 8 seconden) voor het laatst beschreven zijn, worden nog niet naar de vaste schijf geschreven. Ze blijven dus ongewijzigd in de cache staan. Ze hebben een beschermde status. Dit omdat zij de grootste kans om op korte termijn opnieuw beschreven te worden. Maar als zo'n aldoor zich wijzigende buffer al MaxAge (hier 256 s) in de cache staat, dan wordt de buffer alsnog naar de schijf geschreven en krijgt hij het label clean. Totdat hij opnieuw wordt beschreven of wordt opgeheven.
Voor een niet expliciet in seconden opgegeven Maxage geldt de standaardwaarde van 4 maal Synctime. En zal een zich aldoor wijzigende JFS buffer dus tijdens de vierde synchronisatieronde toch naar de vaste schijf geschreven worden. Voor een niet expliciet in seconden opgegeven Bufferidle geldt een standaard waarde van Synctime/8.
Dat ziet u als u de Lazy write parameter zonder Maxage en Bufferidle opgeeft.
[F:\]cachejfs /lw:40
SyncTime: 40 seconds
MaxAge: 160 seconds
BufferIdle: 5 seconds
Cache Size: 600000 kbytes
Min Free buffers: 24000 ( 96000 K)
Max Free buffers: 48000 ( 192000 K)
Lazy Write is enabledNB. De formule MIN(1,SyncTime/8) klopt volgens mij niet, want het minimum van de reeks 1,5 is 1..
Op ftp://ftp.netlabs.org/pub/snapshots/openjfs/ en ftp://ftp.netlabs.org/pub/openjfs/ vindt u de bestanden die bij het OpenJFS project voor OS/2 behoren. Ze zitten niet bij eCS. Het kan zijn dat ze niet de juiste gegevens geven voor uw versie van JFS, maar de uitvoer van deze utilities was op zich wel erg leerzaam. In feite is alles wat ik hier over de JFS cache beweer is op mijn logbestanden van met name het utility cstat (cache statistics) gebaseerd (deductie). Maar deze nauwelijks door IBM of Netlabs gedocumenteerde utilities zijn soms ook heel verwarrend.
Zo zou de bij eCS geleverde JFS cache volgens de uitvoer van os2stats uit vier gelijke delen bestaan: Een NCache, JCache, LCache en een ICache. Terwijl ik in de cstats praktijk vooral met bestanden (c_buffers) en metadata buffers (j_buffers) te maken had. De bestanden bufferende c_buffers domineerden in de normale (bestanden lezende) eCS praktijk, maar de pas ingelezen j_buffers verplaatsen de c_buffers tijdens grote zoekacties op JFS.
Dus bij de CONFIG.SYS instellingen:
IFS=F:\OS2\JFS.IFS /LW:5,20,4 /AUTOCHECK:IGQ /CACHE:500000 RUN=F:\OS2\CACHEJFS.EXE /LW:20 /MIN:20000 /MAX:40000
Ziet u de volgende cachejfs:
[F:\]cachejfs
SyncTime: 20 seconds
MaxAge: 80 seconds
BufferIdle: 2 seconds
Cache Size: 500000 kbytes
Min Free buffers: 2500 ( 10000 K)
Max Free buffers: 5000 ( 20000 K)
Lazy Write is enabledEn os2stats waarden:
[F:\]os2stats
NCache: lookup: 125000
hit: 65536
miss: 50395
enter: 2500
delete: 5000
name2long: 0
JCache: reclaim: 125000
read: 65536
recycle: 50395
lazywrite.awrite: 2500
recycle.awrite: 5000
logsync.awrite: 0
write: 22914
LCache: commit: 125000
page.init: 65536
page.done: 50395
sync: 2500
maxbufcnt: 5000
ICache: n.inode: 125000
reclaim: 65536
recycle: 50395
release: 2500Op het eerste gezicht leek de uitvoer van os2stats te suggereren dat mijn 500000 KB grootte JFS cache door 4 caches van 125000 KB gebruikt werd: de NCache, de JCache, de LCache en de ICache. Want vier maal 125000 levert mijn IFS.JFS /CACHE:500000 op. Maar dat was zeker niet het geval. De waarde 125000 slaat consequent op het aantal geheugenpagina's (buffers genoemd) van de cache in 4 KiB frame pages. En 125000 maal 4 kiB PageFrames levert 500000 KiB op.
De openjfs broncode bevestigt dit. In jfs_cachemgr.h vindt u de constante Cache_Manager Blocksize terug als: #define CM_BSIZE 4096 /* size of a cache buffer */
Het gaat dus niet om vier afzonderlijke caches, maar om de vier hoofdfuncties van een JFS cache, waar de cache blijkbaar alle cache buffers voor mag gebruiken. maar dat heeft ook nogal wat consequenties. Want als een kleine JFS cache met tree een directorylisting uitvoert op een JFS volume, zal de JFS cache recent gecachte bestanden (in de JCache en LCache) er uit gooien om plaats te maken voor bestandsnamen (in de NCache en ICache). Bij het verderop besproken utility cstats gaat het respectievelijk on c_buffers en j_buffers. Maar het omgekeerde vindt ook plaats als ffmepeg grote bestanden converteert. Dan zal de lazy write cache snel gevuld worden.
|
os2stats.exe |
Neem mijn commentaar hierop met een korreltje zout. Ik zou de JFS broncode beter moeten begrijpen, maar dat gaat me nog boven de pet. |
|
NCache: lookup: 125000 hit: 65536 miss: 111883 enter: 20000 delete: 40000 name2long: 0
|
De NCache functie retourneert het inode number van een opgegeven bestandsnaam. Vergelijk deze directory name lookup cache (dnlc) met de Name Server functie van de DNS of het hostbestand dat het IP adres (een 32 bits getal) van een hostnaam geeft. De waarde van NCache: lookup: geeft het aantal beschikbare geheugenpagina's (4 KiB buffers) aan. Deze cache is dus 125000 maal 4 kiB is 500000 KiB groot. Dezelfde (maximum) waarde vindt u terug bij JCache: reclaim, de LCache: commit en ICache: n.inode. De waarde hit bleef bij mij steeds gelijk (65536 of 2^16 oftwel 64 MiB). Bij een twee keer zo kleine cache van 256000 KB (64000 buffers) zag ik 32768 (2^8) staan. Bij Hit, read, page.init en reclaim zag ik steeds dezelfde waarden. De waarde miss: 111883 nam in de tijd af. Maar na een cahejfs opdracht werd de waarde weer gereset. Bij miss, recycle in de JCache, page.done en recycle in de ICache ging het meestal om dezelfde waarden. Maar de andere waarden konden ook iets lager zijn dan miss. Zoals in deze reeks. miss recycle(J) page.done recycle(I) 98494 98494 98493 98493 98482 98482 98482 98481 98477 98477 98477 98477 98475 98475 98474 98474 98466 98466 98466 98466 De waarde enter: 20000 is gelijk aan het aantal Min Free buffers van cachejfs. Voor de waarden enter, lazywrite.awrite, sync en release geldt hetzelfde. De waarde delete: 40000 is het aantal Max Free buffers van cachejfs. Hetzelfde geldt voor delete, recycle.awrite en maxbufcnt. In de waarden van name2long: 0 zag ik geen wijzigingen. Slaat het op de niet gecachte lange bestands- of directorynamen? JFS 3.5 plaatste geen bestanden met namen langer dan 32 tekens in de cache. Onder OS/2 zag ik dit probleem niet. Maar de broncode vermeld wel een waarde DNLCNAMEMAX. |
|
JCache: reclaim: 125000 read: 65536 recycle: 111883 lazywrite.awrite: 20000 recycle.awrite: 40000 logsync.awrite: 0 write: 9493
|
De Jcache is de meta-data buffer cache (zie jfs_bufmgr.c). Het gaat dus om de j_bufs uit cstats. meta-data buffer cache (aka jcache) supporting no-steal, no-force policy for transaction-oriented log-based recovery file system. De JCache: reclaim: geeft het aantal beschikbare geheugenpagina's (4 KiB buffers) aan. De waarde van read: 65536 blijft aldoor gelijk. Deze 64 MiB kan mogelijk op de maximale hoeveelheid gegevens slaan die via een LW transactie gebufferd word. De waarde recycle: 111883 nam aldoor toe. Het gaat hier meestal om dezelfde waarde als miss, page.done en de recycle uit ICache. De waarden van lazywrite.awrite: 20000 en recycle.awrite: 40000 slaan op de Min en Max Free buffers waarden van cachejfs. De waarde logsync.awrite: 0 lijkt constant. De waarde write: 9493 neemt toe zolang u geen cachejfs of format gebruikt. Het gaat volgens mijn experimenten soms om het aantal bestanden (niet de buffers) die een lazy write ondergaan op de actieve schijf. Even later geeft bij mij write: 19053 |
|
LCache: commit: 125000 page.init: 65536 page.done: 111883 sync: 20000 maxbufcnt: 40000 |
Ik vermoed dat hier om de eigenlijke JFS bestanden of buffer cache gaat. Maar de broncode (jfs_bufmgr.c) heeft het weer over de niet door os2stats genoemde data buffer cache (cCache) control. Maar de L kan natuurlijk slaan op lazy write. De JFS Log buffer cache schrijft de logs van de uitgevoerde transacties serieel (de een naar de ander) naar de schijf. Het logbestand is standaard 0.4% van de schijf wordt gebruikt tijdens een chkdsk op de schijf om de bestands- en directoriestructuur te herstellen. Het bevat dus slechts metadata. Commit: 125000 slaat op het aantal geheugenpagina's van 4 KB. De waarde page.init: 65536 bleef aldoor gelijk. De broncode spreekt van # of pages written. Deze 64 MiB is ook de maximale grootte van een allocation group. De waarde page.done: 111883 nam toe. De broncode spreekt van # of page write. De waarde sync: 20000 slaat op de Min Free buffers: 20000 (80000 K) van cachejfs. De broncode spreekt van # of logsysnc(). Evenzo duidt maxbufcnt: 40000 de Max Free buffers: 40000 (160000 K) van cahejfs aan. Maar de broncode noemt het: max # of buffers allocated. |
|
ICache: n.inode: 125000 reclaim: 65536 recycle: 111883 release: 20000 |
De Inode cache bevat ingangen van inodes. Inode operaties zijn volgens IBM-jfs.pdf : Create, lookup, link, unlink file, mkdir, rmdir en rename. De waarde n.inode staat voor het aantal buffers. De waarde reclaim stond constant op 65536. De waarden van recycle: 111883 nam wel toe in de tijd. Maar kan later ook weer gereset worden. De waarde van release: 20000 is dezelfde als de Min Free buffers van cachejfs. |
|
CCache? |
data buffer cache (cCache) control |
Een ander utility is cstats (cache statistics).
[F:\]cstats cachesize 125000 cbufs_protected 77088 hashsize 65536 cbufs_probationary 1249 nfreecbufs 45748 cbufs_inuse 0 minfree 2500 cbufs_io 9176 maxfree 5000 jbufs_protected 557 numiolru 0 jbufs_probationary 351 slrun 77645 jbufs_inuse 0 slruN 83332 jbufs_io 0 Other 7 jbufs_nohomeok 0
|
[F:\]cstats |
Met cstats heb ik vrij veel statistiek kunnen bedrijven dankzij een handig REXX script van Joachim Benjamins dat de ctstats uitvoer bijv om de seconde naar een cvs-bestand kon schrijven. Hiermee kon ik de cache dynamiek bestuderen. |
|
cachesize 125000 |
De constante waarde cachesize is het totaal aantal buffers in de lazy write cache. Iedere buffer zit in een pageframe van 4 KiB. De grootte van de cache in KiB is dus 4 maal het aantal buffers: 4*125000 is levert de /CACHE:500000 waarde in de CONFIG.SYS op. De waarde cachesize is de som van de variabele waarden nfreecbufs, other, cbufs_protected, cbufs_probationary, cbufs_inuse, cbufs_io, jbufs_protected, jbufs_probationary, jbufs_inuse, jbufs_io en jbufs_nohomeok. Oftewel: als er voor een actuele gecachte lazy write schrijfactie cbufs_protected nodig zijn, gaat dat ten koste van andere buffers. In de eerste instantie van de vrije (nfreecbufs) buffers, maar als die op zijn ook van de dynamische cbufs_probationary buffers. En als die op zijn worden de cbufs_protected gewogen. De waarden hashsize, minfree, maxfree, slruN zijn constanten. Minfree en maxfree zijn dynamisch in te stellen met cachejfs /min:x /max:y. De variabele waarde slrun bleek (voor zover ik kon nagaan) steeds de som te zijn van de van protected buffers (cbufs_protected + jbufs_protected). En had een maximum van slruN. En de waarde van slruN was steeds weer twee derde van de cachesize. De hele OS/2 JFS cache (cachesize) kan daarom grofweg ingedeeld worden in twee secties: 1). Een relatief statisch deel. Ze bevatten protected buffers die door cstats met de waarde slrun (=cbufs_protected + jbufs_protected) aangegeven. Dit deel is maximaal 2/3 van de cache (de waarde van slruN). 2). Een dynamisch deel van de cache. Het dynamische deel (cachesize - slrun) is minimaal 1/3 van de cache. In dit deel zijn de buffers niet beschermd (protected) maar voorlopig (probationary period: in een proefperiode) aangesteld. Dit deel van de cache wordt uit de vrije buffers gerecruteerd: vrije buffers <=> probationary buffers <> protected buffers. |
|
hashsize 65536 |
De constante hashsize lijkt af te hangen van de cache grootte. 65536 is 2 tot de macht 16 oftewel 64 MiB. De cache manager hanteert hash lists van groepen buffers (bij c_buffers) om uit te maken of ze tussendoor veranderd zijn. Als dat het geval moeten die veranderde buffers via hun veranderde hash opgespoord worden en als dirty gelabeld worden. Dirty buffers kunnen niet zomaar opgeheven worden. De inhoud zal eerst naar de schijf geschreven moeten worden. De clou is dat de cache de inhoud van de buffers niet bit voor bit met de blokken op de schijf vergelijkt (dat is teveel werk), maar steeds nagaat of een uit de buffer berekend controlegetal veranderd is. Uit jfs_bufmgr.c: Hashlist (per system): a doubly-linked list per hash class; each named buffer (a buffer that has a devices's block assigned to it) is placed on a hashlist by hash class to be reclaimed. (valid vs invalid B_STALE/B_ERROR ?) |
|
nfreecbufs 45748 |
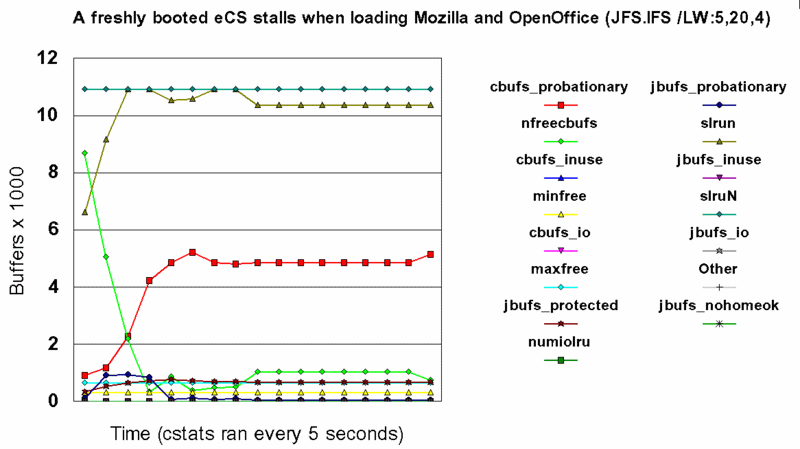
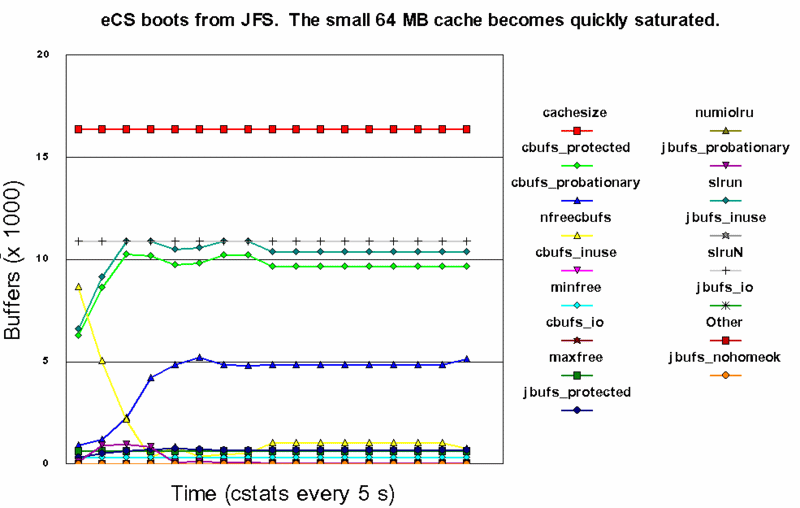
De nfreecbufs is het aantal vrije buffers. Bij het opstarten van het systeem is nfreecbufs (groen) even groot als cachesize. Maar naarmate er meer bestanden en directories door de cache ingelezen worden, neemt het aantal vrije buffers af ten gunste van de cbufs (bestanden cache) en jbufs (directory en namen cache). Bij de onderstaande grafiek werd eCS van JFS geboot. JFS werd standaard met IFS=G:\OS2\JFS.IFS /LW:5,20,4 /AUTOCHECK:* geladen. Het leverde een 64 MiB (16384 4 KiB buffers) grote cache op. De cstats timing (een sample per 5 seconden) begon na het laden van startup.cmd. Via de Startup folder werden o.a. Mozilla OpenOffice geladen. Het doel was te onderzoeken of de 64 MiB cache nog in evenwicht kwam. Dat was niet het geval. De slrun waarde was dramatisch laag. Vrijwel de hele cache was gevuld met tijdelijke data. En de vrije buffers (nodig om iest snel in te lezen of te beschrijven) waren aldoor minimaal.
Als de vrije buffers opraken zal zelfs een DIR het niet meer doen. Zie: PJ27832. Deze situatie is te voorkomen door de minfree waarde te verhogen en/of het cache synchronisatie-interval te verkorten. Uit jfs_bufmgr.c: freelist (per system): a circular doubly-linked list; a buffer that is not B_BUSY and not B_NOHOMEOK is on the freelist where it can be either reclaimed or recycled. |
|
minfree 2500 |
De waarde minfree is het minimale aantal vrije buffers die de cache moet vrijhouden. Standaard gaat het om 2% van cachesize. Minfree is in te stellen op de prompt met cachejfs /minfree:2500 of cachejfs /min:2500. De waarde moet wel minder dan MaxFree zijn, anders brengt u de cache (en OS/2) in problemen. |
|
maxfree 5000 |
De waarde maxfree is het maximale aantal vrije buffers waarnaar gestreefd wordt. Standaard gaat het om 4% van cachesize. In te stellen via cachejfs /maxfree:5000 of cachejfs /max:5000 Maxfree moet aanzienlijk groter zijn MinFre. Bijv. twee keer zo groot, maar wel kleiner dan slruN. |
|
numiolru 0 |
Deze waarde staat meestal op 0, maar nam flink toe tijdens een I/O intensieve fill test. Daarna zakte de waarde weer naar snel naar 0. LRU slaat op het least recently used (LRU) cache vervangingsalgoritme. Een header definieert de waarde als num of cbuf in i/o for lru. [F:\]cachejfs /lw:200
SyncTime: 200 seconds
MaxAge: 800 seconds
BufferIdle: 25 seconds
Cache Size: 400000 kbytes
Min Free buffers: 2000 ( 8000 K)
Max Free buffers: 4000 ( 16000 K)
Lazy Write is enabledFill test opstarten [K:\test]F:\PROGRAMS\FILL\FILL.EXE k:\test\test7 4096 Writing file k:\test\test7 of size 4096 MB. [[F:\]cstats cachesize 100000 cbufs_protected 9444 hashsize 65536 cbufs_probationary 48336 nfreecbufs 1967 cbufs_inuse 0 minfree 2000 cbufs_io 33360 maxfree 4000 jbufs_protected 6876 numiolru 235 jbufs_probationary 0 slrun 16320 jbufs_inuse 0 slruN 66666 jbufs_io 0 Other 7 jbufs_nohomeok 10 Fill test is klaar: [K:\test]F:\PROGRAMS\FILL\FILL.EXE k:\test\test7 4096 Writing file k:\test\test7 of size 4096 MB. Time elapsed : 113 seconds. [F:\]cstats cachesize 100000 cbufs_protected 9426 hashsize 65536 cbufs_probationary 76319 nfreecbufs 2136 cbufs_inuse 0 minfree 2000 cbufs_io 5224 maxfree 4000 jbufs_protected 6876 numiolru 0 jbufs_probationary 1 slrun 16302 jbufs_inuse 0 slruN 66666 jbufs_io 0 Other 7 jbufs_nohomeok 11 Even later is de lazy write cache ook klaar (cbufs_io 0). [F:\]cstats cachesize 100000 cbufs_protected 9426 hashsize 65536 cbufs_probationary 81543 nfreecbufs 2136 cbufs_inuse 0 minfree 2000 cbufs_io 0 maxfree 4000 jbufs_protected 6876 numiolru 0 jbufs_probationary 1 slrun 16302 jbufs_inuse 0 slruN 66666 jbufs_io 0 Other 7 jbufs_nohomeok 11 Niet veel later bleek het systeem instabiel te worden (toeval?). De fill test bij een kleinere cache. [F:\]cstats cachesize 25000 cbufs_protected 215 hashsize 16384 cbufs_probationary 11440 nfreecbufs 461 cbufs_inuse 0 minfree 500 cbufs_io 11816 maxfree 1000 jbufs_protected 1060 numiolru 282 jbufs_probationary 0 slrun 1275 jbufs_inuse 0 slruN 16666 jbufs_io 0
Other 7 jbufs_nohomeok 1 |
|
slrun 77645 |
De waarde slrun (segmented lru number) was gelijk aan de som van cbufs_protected + jbufs_protected. Slrun slaat dus op het actuele protected deel van de cache. De waarde werd nooit (veel) hoger dan slruN constante oftewel 2/3 van de cache. Want als dat gebeurt (cachemgr.slrun >= cachemgr.slruN) verdwijnen de least recently used protected buffers in de staart van het proefsegment, waar ze opnieuw een kans krijgen om benaderd te worden en dan opnieuw protected worden. In de broncode (jfs_bufmgr.c) kunt u dit nalezen onder het kopje #ifdef _JFS_HEURISTICS_SLRU. In het diagram hieronder ziet u dit weergegeven na het booten van eCS via JFS met een 64 MiB cache. De cachesize (rood) was 16384 en de slrunN (grijs) was 2/3 hiervan (10922). De slrunN waarde in MiB was dus 10922 buffers van 4 KiB / 1024 = 42.7 MiB. De 16384 vrije buffers waarmee de cache begon (geel) zijn na 20 seconden opgeraakt. De laagste waarde was 350 bij een minfree waarde van 327 (maxfree was 655). De vrije buffers namen plaats voor cbufs_protected (groen) en cbufs_probationary (blauwe driehoekjes). De slrun (azuur) benadert slrunN doordat veel cbufs beschermd zijn (cbufs_protected). En dan is deze relatief kleine 64 MB cache verzadigd. In die situatie (slrun+slruN) moet de cache als het een nieuw bestand (cache miss) eenmalig inleest, de al vaker maar niet zo recent benaderde protected c_buffers lozen. En dus zal de cache hit rate waarschijnlijk snel dalen. Omdat we ervan uit kunnen gaan dat protected JFS buffers die recent meer dan een keer benaderd zijn, meer kans maken om opnieuw benaderd te worden dan probational buffers die recent maar een keer benaderd zijn. Want de probational buffers bevatten veel bestanden die in korte tijd maar een keer benaderd worden. Bijv. de buffers van een MPEG bestand of van slechts eenmaal ingelezen uitvoerbare bestanden (dus niet cmd.exe).
|
|
slruN 83332 |
slruN is een constante. Het segmented LRU getal was 83332 bij cachesize 125000 en 66666 bij cachesize 100000 (dus steeds ongeveer 2/3 van de buffers). Dit blijkt ook uit de broncode: jfs_bufmgr.c definieert cachemgr.slruN = (nBuffer/3)*2. Het betekent dat niet meer dan 2/3 van de cachebuffers protected kunnen zijn. Dus als de slriun = slruN |
|
Other 7 |
Blijkbaar een restcategorie. |
|
cbufs_protected 77088 |
De waarde cbufs_protected slaat op beschermde buffers met bestandsinhoud in de cache. Het gaat o.a. om buffers die korter geleden dan bufferidle beschreven zijn, maar tijdens een fill test met een wat kleinere cache zag ik ook ook cbufs_protected 0 bij BufferIdle 20 seconds staan: [F:\]cstats
cachesize 25000 cbufs_protected 0
hashsize 16384 cbufs_probationary 1368
nfreecbufs 475 cbufs_inuse 0
minfree 500 cbufs_io 23144
maxfree 1000 jbufs_protected 0
numiolru 77 jbufs_probationary 0
slrun 0 jbufs_inuse 1
slruN 16666 jbufs_io 1
Other 7 jbufs_nohomeok 4
[F:\]cachejfs
SyncTime: 50 seconds
MaxAge: 200 seconds
BufferIdle: 20 seconds
Cache Size: 100000 kbytes
Min Free buffers: 500 ( 2000 K)
Max Free buffers: 1000 ( 4000 K)
Lazy Write is enabledBlijkbaar kunnen de beschermde bestanden tijdens heftige I/O tijdelijk naar numiolru, cbufs_io verhuizen. Voor de eveneens op 0 gestelde jbufs_protected (bevat data over directories) geldt een analoog verhaal (met jbufs_io van 1 en jbufs_nohomeok van 13). De fill test eindigde zo: Writing file k:\test\test7 of size 4096 MB. Time elapsed : 144 seconds. ------------------------------------------------- cachesize 25000 cbufs_protected 31 hashsize 16384 cbufs_probationary 22623 nfreecbufs 839 cbufs_inuse 0 minfree 500 cbufs_io 328 maxfree 1000 jbufs_protected 1159 numiolru 0 jbufs_probationary 0 slrun 1190 jbufs_inuse 0 slruN 16666 jbufs_io 0 Other 7 jbufs_nohomeok 13 ------------------------------------------------- Sleep 5 seconds ------------------------------------------------- cachesize 25000 cbufs_protected 34 hashsize 16384 cbufs_probationary 22960 nfreecbufs 827 cbufs_inuse 0 minfree 500 cbufs_io 0 maxfree 1000 jbufs_protected 1159 numiolru 0 jbufs_probationary 0 slrun 1193 jbufs_inuse 0 slruN 16666 jbufs_io 0 Other 7 jbufs_nohomeok 13 Met een nog langere idle time cachejfs /lw:100,200,50 bleven er wel bestanden in cbufs_protected staan. SyncTime: 100 seconds
MaxAge: 200 seconds
BufferIdle: 50 seconds
Cache Size: 100000 kbytes
Min Free buffers: 500 ( 2000 K)
Max Free buffers: 1000 ( 4000 K)
Lazy Write is enabled
-------------------------------------------------
Writing file k:\test\test7 of size 4096 MB.
Time elapsed : 145 seconds.
-------------------------------------------------
cachesize 25000 cbufs_protected 30
hashsize 16384 cbufs_probationary 22409
nfreecbufs 983 cbufs_inuse 0
minfree 500 cbufs_io 400
maxfree 1000 jbufs_protected 1152
numiolru 0 jbufs_probationary 0
slrun 1182 jbufs_inuse 0
slruN 16666 jbufs_io 0
Other 7 jbufs_nohomeok 19
-------------------------------------------------
Sleep 5 seconds
-------------------------------------------------
cachesize 25000 cbufs_protected 25
hashsize 16384 cbufs_probationary 22814
nfreecbufs 980 cbufs_inuse 0
minfree 500 cbufs_io 0
maxfree 1000 jbufs_protected 1158
numiolru 0 jbufs_probationary 3
slrun 1183 jbufs_inuse 0
slruN 16666 jbufs_io 0
Other 7 jbufs_nohomeok 13De cbufs_io en cbufs_probationary zullen grotendeels uit de door fill aangemaakte bestanden bestaan. Met /lw:5 (en Bufferidle 0) waren de cbufs_protected snel opgeofferd. [F:\]cstats cachesize 25000 cbufs_protected 152 hashsize 16384 cbufs_probationary 23189 nfreecbufs 617 cbufs_inuse 0 minfree 500 cbufs_io 0 maxfree 1000 jbufs_protected 1032 numiolru 0 jbufs_probationary 0 slrun 1184 jbufs_inuse 1 slruN 16666 jbufs_io 0 Other 7 jbufs_nohomeok 2 [F:\]cstats cachesize 25000 cbufs_protected 0 hashsize 16384 cbufs_probationary 17970 nfreecbufs 573 cbufs_inuse 0 minfree 500 cbufs_io 5472 maxfree 1000 jbufs_protected 974 numiolru 0 jbufs_probationary 0 slrun 974 jbufs_inuse 1 slruN 16666 jbufs_io 0 Other 7 jbufs_nohomeok 3 De jbufs_protected lijken daarentegen relatief beschermd. Gelukkig maar, want zij vervullen een even belangrijke rol voor JFS als de FAT tabel Cache onder FAT. |
|
cbufs_probationary 1249 |
Het gaat hier om het aantal voorwaardelijke bestandenbuffers in de cache. Probationary betekent zoiets als: zich bevindend in een proefperiode. Wat is de achtergrond hiervan? Denk eens na over het volgende probleem. Een al dan niet uitvoerbaar bestand wordt op verzoek van een programma geopend en zijn buffers komen dus in de read-ahead cache terecht. Maar de read-ahead cache weet de bedoeling van een programma niet. Het kan om een nuttige read-ahead actie op de vaste schijf gaan. In dat geval zullen de JFS buffers op korte termijn opnieuw of bij read-ahead alsnog ingelezen worden en zullen die cbufs_probationary (als die nog in de cache buffers aanwezig zijn) naar de cbufs_protected afdeling van de statische cache bevorderd worden. Maar als er ineens veel vrije buffers voor nieuwe zaken nodig zijn (bijv. bij het gecached inlezen of wegschrijven van nieuwe bestanden of een zoekactie op JFS), zullen als de vrije buffers opraken de onbeschermde buffers (cbufs_probationary) als eerste worden ontslagen. De buffers komen dan vrij om plaats te maken voor buffers met de nieuwe inhoud. Dit bleek uit overduidelijk uit mijn fill testen op JFS. De cbufs_probationary waarde van recent geopende bestanden schommelt dus meer op en neer dan die van de cbufs_protected die hun waarde (via meerdere recente I/O operaties) al hebben bewezen. En zeker meer dan de nog beter beschermde statische jbufs_protected die zoiets als de essentiële FAT cache zijn voor JFS.
Een voorbeeld: terwijl ik dit type zijn mijn cache statistieken: [F:\]cachejfs
SyncTime: 20 seconds
MaxAge: 120 seconds
BufferIdle: 5 seconds
Cache Size: 500000 kbytes
Min Free buffers: 2500 ( 10000 K)
Max Free buffers: 5000 ( 20000 K)
Lazy Write is enabled
[F:\]cstats
cachesize 125000 cbufs_protected 27141
hashsize 65536 cbufs_probationary 91229
nfreecbufs 3539 cbufs_inuse 0
minfree 2500 cbufs_io 0
maxfree 5000 jbufs_protected 2572
numiolru 0 jbufs_probationary 512
slrun 29713 jbufs_inuse 0
slruN 83332 jbufs_io 0
Other 7 jbufs_nohomeok 0De opdracht tree wordt eerst uitgevoerd op I en dan op K. Tree geeft alleen maar de directorystructuur weer en de mappen aanwezige bestanden. [F:\]df
Filesystem 1K-blocks Used Available Use% Mounted on
33316916 25911708 7405208 78% I:/
Backup 194644752 141335552 53309200 73% K:/Ik laat alleen essentiële uitvoer zien. Other en [F:\]start tree i: [F:\]cstats cachesize 125000 cbufs_protected 27148 hashsize 65536 cbufs_probationary 91226 nfreecbufs 3058 cbufs_inuse 0 minfree 2500 cbufs_io 0 maxfree 5000 jbufs_protected 3030 numiolru 0 jbufs_probationary 530 slrun 30178 jbufs_inuse 1 slruN 83332 jbufs_io 0 In eerste instantie nemen vooral de vrije buffers af (hierboven). Maar even later moeten de cbufs_probationary het ontgelden. Ze maken plaats voor nieuwe vrije buffers (nfreecbufs) die door tree's activiteit omgezet worden in jbufs_protected [F:\]cstats cachesize 125000 cbufs_protected 15236 hashsize 65536 cbufs_probationary 3144 nfreecbufs 95969 cbufs_inuse 0 minfree 2500 cbufs_io 0 maxfree 5000 jbufs_protected 10289 numiolru 0 jbufs_probationary 354 slrun 25525 jbufs_inuse 1 slruN 83332 jbufs_io 0 [F:\]cstats cachesize 125000 cbufs_protected 15259 hashsize 65536 cbufs_probationary 3136 nfreecbufs 84669 cbufs_inuse 0 minfree 2500 cbufs_io 0 maxfree 5000 jbufs_protected 21581 numiolru 0 jbufs_probationary 348 slrun 36840 jbufs_inuse 0 slruN 83332 jbufs_io 0 Als tree klaar is op I: blijkt het aandeel cbufs_protected nagenoeg gelijk, maar zijn de jbufs_protected fors toegenomen. De slrun Ihet statisch deel van de ache ) is flink gestegen, naar de cache is nog lang niet verzadigd met een nfreecbufs van 84669 (een 64 MB JFS cache zou al veel eerder in de synchronisatie problemen gekomen zijn: de waarde slrun zou slruM al lang benaderd hebben). Om te zien hoe het verder gaat start ik tree nu op voor drive K. Deze backup schijf bevat heel veel bestanden (o.a. dsync backups en een Smart cache). Tree doet er dan ook meer dan een kwartier over. [F:\]start tree k: [F:\]cstats cachesize 125000 cbufs_protected 15222 hashsize 65536 cbufs_probationary 3140 nfreecbufs 58389 cbufs_inuse 0 minfree 2500 cbufs_io 0 maxfree 5000 jbufs_protected 47755 numiolru 0 jbufs_probationary 486 slrun 62977 jbufs_inuse 1 slruN 83332 jbufs_io 0 De vrije buffers nemen af. De door tree blijkbaar aldoor hergebruikte jbufs_protected nemen toe. Deze buffers zullen in ieder geval de steeds weer opnieuw benaderde stamgedeelten van de directoryboom bevatten. [F:\]cstats cachesize 125000 cbufs_protected 15251 hashsize 65536 cbufs_probationary 3145 nfreecbufs 37766 cbufs_inuse 0 minfree 2500 cbufs_io 0 maxfree 5000 jbufs_protected 60885 numiolru 0 jbufs_probationary 7945 slrun 76136 jbufs_inuse 1 slruN 83332 jbufs_io 0 [F:\]cstats cachesize 125000 cbufs_protected 15247 hashsize 65536 cbufs_probationary 3175 nfreecbufs 30977 cbufs_inuse 0 minfree 2500 cbufs_io 0 maxfree 5000 jbufs_protected 63720 numiolru 0 jbufs_probationary 11873 slrun 78967 jbufs_inuse 1 slruN 83332 jbufs_io 0 [F:\]cstats cachesize 125000 cbufs_protected 15259 hashsize 65536 cbufs_probationary 3164 nfreecbufs 23212 cbufs_inuse 0 minfree 2500 cbufs_io 0 maxfree 5000 jbufs_protected 67765 numiolru 0 jbufs_probationary 15592 slrun 83024 jbufs_inuse 1 slruN 83332 jbufs_io 0 Other 7 jbufs_nohomeok 0 Tree was al klaar op I en nu ook op K: De cache bevat nog maar heel weinig bestanden in het statische deel. De slrun waarde benaderd slruN op een haar en de 500 MiB cache is duidelijk verzadigd. Vrijwel de gehele statische cache wordt ingenomen door directorystructuurinformatie. [F:\]cstats cachesize 125000 cbufs_protected 83 hashsize 65536 cbufs_probationary 27580 nfreecbufs 4791 cbufs_inuse 0 minfree 2500 cbufs_io 0 maxfree 5000 jbufs_protected 83248 numiolru 0 jbufs_probationary 9289 slrun 83331 jbufs_inuse 1 slruN 83332 jbufs_io 0 Other 7 jbufs_nohomeok 1 Komt de cache weer in evenwicht? Natuurlijk, maar uit ervaring weet ik dat jbufs_protected lang in cache blijven zitten. Het voordeel is FM/2 de mappen op K: nu razendsnel inleest en dat ook smart cache bestanden sneller vindt. [F:\]cstats cachesize 125000 cbufs_protected 16328 hashsize 65536 cbufs_probationary 36221 nfreecbufs 2874 cbufs_inuse 0 minfree 2500 cbufs_io 0 maxfree 5000 jbufs_protected 66995 numiolru 0 jbufs_probationary 2566 slrun 83323 jbufs_inuse 0 slruN 83332 jbufs_io 0 Other 7 jbufs_nohomeok 9 Smartcache zorgde er hier voor dat de jbufs_nohomeok toenamen. Dit gebeurde als ik Smart cache beproefde door heel veel URLS tegelijkertijd via Firefox's Open in all tabs opende. |
|
cbufs_inuse 0 |
Het aantal bestanden buffers dat door programma's geopend zijn. Zo'n buffer is dan tijdelijk geblokkeerd voor andere programma's. Ik zag bijna altijd een waarde van 0, soms een 1. |
|
cbufs_io 0 |
De cbufs_io is bij gewoon gebruik van de cache vaak 0 of gering. Dat komt omdat de lazy write cache de beschreven data het liefst op een rustig moment naar de vaste schijf schrijft. Een lazy write valt als het goed is niet op. Maar de cbufs_io nemen dramatisch toe tijdens een fill test die in no time grote bestanden in het cache geheugen aanmaakt. Dat doet fill natuurlijk door lege buffers eenmalig te beschrijven (de lila ncfreebufs nemen dus meteen af), die daarna probationary dirty buffers worden (de geel gekleurde stijgende lijnen). Maar als fill doorgaat met lege buffers te vullen, moeten er eerst nieuwe vrije buffers vrijkomen, zodat er evenveel LRU probationary dirty buffers kunnen ontstaan als er cbufs_io naar de schijf geschreven moeten worden. U ziet dat in onderstaande grafiek terug doordat na enige tijd (cache io evenwicht) de gele lijn van de cbufs_proarionary het spiegelbeeld vormt van de rode lijn van de cbufs_probationary. Die rood gekleurde cbufs_io lazy write stoom gaat ook nog enige tijd door nadat het systeem aangeeft dat de bestanden (in de cache) geschreven zijn. De LED van de harde schijf en de cbufs_io waarde geeft aan dat er nog veel vertraagde doorvoer is.
Tijdens deze test was de SyncTime 5 seconden. En pas na 4 seconden mochten de gevulde buffers naar schijf geschreven worden. [E:\]cachejfs
SyncTime: 5 seconds
MaxAge: 20 seconds
BufferIdle: 4 seconds
Cache Size: 400000 kbytes
Min Free buffers: 2000 ( 8000 K)
Max Free buffers: 4000 ( 16000 K)
Lazy Write is enabledDe SyncTime van 5 seconden is terug te vinden in de om de 5 seconden verschijnende lazy write cbufs_io pieken. Maar de BufferIdle waarde van 4 seconden laat zich ook gelden. Sommige IO pieken verschijnen om de de 4 in plaats van om de 5 seconden. Alleen de laatste IO piek doet er langer over (6 seconden). Dat was de lazy write die er voor zorgde dat de led van de vaste schijf nog brandde terwijl fill aangaf dat hij (in het cache geheugen) al klaar was. Maar deze lazy write opdracht werd niet opgejaagd door io operaties. |
|
jbufs_protected 557 |
Deze buffers bevatten informatie over de directorystructuur en bestanden (meta-data cache). meta-data buffer cache (aka jcache) supporting no-steal, no-force policy for transaction-oriented log-based recovery file system. De waarde hiervan nam snel toe met de opdracht tree drive:\ die de bestanden in een directoryboom weergeeft. Het ging om een grote schijf met 120 GiG aan bestanden. [F:\]cstats cachesize 125000 cbufs_protected 3457 hashsize 65536 cbufs_probationary 1721 nfreecbufs 2789 cbufs_inuse 0 minfree 2500 cbufs_io 0 maxfree 5000 jbufs_protected 79873 numiolru 0 jbufs_probationary 37152 slrun 83330 jbufs_inuse 1 slruN 83332 jbufs_io 0 Other 7 jbufs_nohomeok 0 De toename van de jbufs ging ten koste van de vrije pool (nfreecbufs) en later ook van de cbufs_probationary en cbufs_protected. Hieronder het effect van een zoekactie met FC/2 naar *.jpk op alle JFS schijven bij een relatief kleine cache (100 MiB). De jbufs nemen enorm toe: [F:\]cstats cachesize 25000 cbufs_protected 1 hashsize 16384 cbufs_probationary 6 nfreecbufs 518 cbufs_inuse 0 minfree 500 cbufs_io 0 maxfree 1000 jbufs_protected 16665 numiolru 0 jbufs_probationary 7802 slrun 16666 jbufs_inuse 1 slruN 16666 jbufs_io 0 Other 7 jbufs_nohomeok 0 Slechts een bestand is nog beschermd door de cache! De waarde van slrun neem toe tot het maximum (slruN). Vrijwel de gehele statische cache bestaat nu uit metadata m.b.t. de directory structuur. |
|
jbufs_probationary 351 |
Ook jbufs_probationary bevatten informatie over de directorystructuur en bestanden. Ze nemen snel toe tijdens het maken van grote bestanden en directorylistings. Probationary ("proeftijd") buffers hebben een voorlopiger karakter dan protected buffers. Waarschijnlijk gaan de meeste recent benaderde jbufs_probationary over naar jbufs_protected. De rest komt weer vrij voor meer urgentere doeleinden zoals bij onderstaande test. Het aantal jbufs is verhoogd door een grote directorylisting aan te maken. [F:\]cstats cachesize 100000 cbufs_protected 8181 hashsize 65536 cbufs_probationary 305 nfreecbufs 58608 cbufs_inuse 0 minfree 2000 cbufs_io 0 maxfree 4000 jbufs_protected 18479 numiolru 0 jbufs_probationary 14420 slrun 26660 jbufs_inuse 0 slruN 66666 jbufs_io 0 Other 7 jbufs_nohomeok 0 De fill test maakt in korte tijd grote nieuwe bestanden op JFS aan. [K:\test]F:\PROGRAMS\FILL\FILL.EXE k:\test\test1 64 Writing file k:\test\test1 of size 64 MB. Time elapsed : 0 seconds. [K:\test]F:\PROGRAMS\FILL\FILL.EXE k:\test\test2 128 Writing file k:\test\test2 of size 128 MB. Time elapsed : 2 seconds. [K:\test]F:\PROGRAMS\FILL\FILL.EXE k:\test\test3 256 Writing file k:\test\test3 of size 256 MB. Time elapsed : 6 seconds. [K:\test]F:\PROGRAMS\FILL\FILL.EXE k:\test\test3 512 Hoe pakt de cache dit aan? Eerst worden de vrije buffers geconsumeerd. Maar het aantal vrije buffers (nfreecbufs 58608) raakt snel op. Bij onderstaande cstats tijdens de fill test blijkt de waarde van nfreecbufs (1999) al minder dan minfree (2000) te zijn. De cache moet dus reorganiseren. Wie moet eruit voor wie? We concluderen dat de nieuwe bestanden terecht komen in de cbufs_io buffers (20448) en cbufs_probationary (50870). De jbufs_probationary zijn nagenoeg verdwenen. [F:\]cstats cachesize 100000 cbufs_protected 8182 hashsize 65536 cbufs_probationary 50870 nfreecbufs 1999 cbufs_inuse 0 minfree 2000 cbufs_io 20448 maxfree 4000 jbufs_protected 18483 numiolru 8 jbufs_probationary 8 slrun 26665 jbufs_inuse 0 slruN 66666 jbufs_io 0 Other 7 jbufs_nohomeok 3 Een jbuf_probationary bevat een eerder gebruikte directorystructuur. De vrije buffers zijn op. Is de buffer nog nodig? Indien hij lui beschreven wordt: jbuf_probationary wordt jbuf_io en later weer een jbuf_probrationary. Indien recent hergebruikt: jbuf_probationary wordt jbuf_protected. Indien niet recent hergebruikt: jbuf_probationary wordt vrije buffer (freecbuf). Fill vult vrije buffers: freecbuf wordt cbuf_io (dirty) wordt cbuf_probationary (weggeschreven). Een cbuf_probationary kan bij hergebruik een cbuf_protected worden of anders een freecbuf. |
|
jbufs_inuse 0 |
Vrijwel altijd 0. Wed 1 tijdens het verplaatsen vaan en grote map van K naar Q op JFS. |
|
jbufs_io 0 |
Vrijwel altijd 0. |
|
jbufs_nohomeok 0 |
De waarde van jbufs_nohomeok is normaal 0, maar kan tijdens fill testen toenemen. Ook als de proxy smart cache gestressed wordt, worden de veranderde jbufs blijkbaar later bijgewerkt. Bij pure leesacties veranderen ze niet. Uit jfs_bufmgr.c: A buffer is made B_NOHOMEOK when it is modified and not committed yet. A nohomeok buffer returns to homeok state when COMMIT record for the transaction which updated the page is written to log. |
Het utility xchklog is mager gedocumenteerd.
XCHKLOG Required parameter missing: device specification
Usage: xchklog [-L[:N|:P]] [-F<filename>] Device
[F:\]G:\OS2BIN\drv\openjfs\xchklog.exe -L -F g:\var\log\xchklog.log g:
chkdsk service log selected: MOST RECENT
XCHKLOG P superblock is valid.
XCHKLOG Most recent chkdsk service log extracted into: \chkdsk.new
jlogview -abcfhinrstuv logfile
-a print detailed record data
-b terminate search at log start
-c check afterdata against disk
-p dump page header and trailer
-f force use of active log
-h print record header data
-i ino number search on inode number
-n search string search after data for string
-r record type search on record type
-s log header information
-t transid search on transaction id
-u uncommitted records
-v vol number search on volume number
Diskettes en vaste schijven worden in blokken afgelezen en beschreven (block devices). Tijdens het inlezen van de sectoren van een 512 KiB FAT diskette werden door DOS buffers van 512 bytes gebruikt. Deze kwamen overeen met de sectoren waarin FAT (op kleinere schijven) en HPFS data opsloegen. En omdat de toegang tot de diskette traag is, had het zin om meteen al een paar buffers vooruit gelezen. Zeker omdat DOS een single tasking user systeem was, waar bij het lopende programma alsmaar door kon gaan. De DOS buffers instelling (BUFFERS=number, read-ahead number) levert dus een primitieve read ahead cache op, waar meerdere programma's (zowel het programma als de virusscanner) gebruik van konden maken.
Maar ook op een pre-emptive multitasking besturingssysteem hebben read ahead buffers zin: Een programma kan hierdoor zijn time-slices beter benutten. Want dat wat al vooraf ingelezen is kan meteen verwerkt worden. Anders (bij een schijfbenadering) wordt het programma in de wachtstand gezet en moet het wachten op zijn volgende door de I/O is ready interrupt gestuurde beurt.
De JFS cache maakt onder OS/2 gebruik van zijn eigen buffers. En dat is wel logisch, want de standaard schijfbuffers van OS/2 zouden een flessenhals vormen bij de doorvoer van de grote bestanden en het lezen van de directorystructuren van het JFS bestandssysteem. OS/2 is geen Linux of AIX waarin vrijwel al het vrije geheugen aan de buffers van het virtuele bestandssysteem (VFS) toegewezen worden.
JFS maakt gebruik van de 4 KiB PageFrames in het systeemgeheugen. De standaard blokgrootte van 4 KiB betekent dat ieder JFS blok in een PageFrame van 4 KiB geladen wordt. Deze standaarde JFS blokgrootte levert meer dan acht maal zo veel verspilling (slack) op per bestand dan de 512 KiB sectoren van HPFS, maar de JFS cache kan dan wel optimaal gebruik maken van de 4 KiB pageframes van de processor. Als uw JFS cache over voldoende werkgeheugen beschikt maakt het JFS dus sneller.
De in de JFS cache en LVM ingebouwde bufferzone kan evenals de statische JFS cache sec vele honderden megabytes groot zijn. De beperkingen worden slechts uitgemaakt door uw fysieke geheugen en de virtuele adresruimte van het systeemgeheugen onder eCS. Maar u moet deze buffers wel expliciet met de /CACHE waarde van de JFS.IFS driver activeren.
Standaard krijgt de JFS.IFS driver slechts 12,5 % van het beschikbare RAM met een maximum van 64 MiB. En dat is doorgaans veel te krap bemeten.
Onder AIX en Linux geldt dat - als er vrij geheugen over is - dat automatisch toebedeeld wordt aan de vrije buffers van het virtuele bestandssysteem. En deze dynamische buffers kunnen door de JFS driver gebruikt worden om de schijf te cachen. Maar onder OS/2 is de zaak lastiger omdat u niet over vrije buffers beschikt buiten die van de JFS cache om. De via de CONFIG.SYS opdracht ingestelde JFS.IFS /CACHE:waarde is een constante: Maximaal 2/3 ervan kan redelijk statisch zijn (de slruN waarde) en de rest gaat naar de vrije, io en voorwaardelijke JFS buffers.
Onder Linux zouden uw dynamische in buffers omgezette vrije geheugen door de JFS cache kunnen worden geclaimd, maar op een 2 GiB eCS systeem met een vooraf op 512 MIB vast ingestelde JFS cache kunt u gemakkelijk nog 1 GiB geheugen vrij hebben zonder dat de JFS cache het kan benutten. Want die heeft u op maximaal 512 MIB ingesteld. Alle dynamiek (vrije buffers, protected, io, nohome of probationary buffers) bevinden zich binnen het met de JFS.IFS /CACHE:waarde ingestelde kernel gebied.
Stel dus de op AIX (met veel vrije buffers) gebaseerde JFS cache dus ruim in. Meer concreet: geef het vrije geheugen dat u overhoudt aan JFS. Bedenk dat de overhead van het intern 64 bits JFS bestandssysteem vele megabytes (wellicht gigabytes op terabyte grote schijven) groter is dan we gewend zijn van 16 bits FAT (128 KiB per FAT Tabel), 16/32 bits HPFS (300 kiB + cache) bestandssystemen. En dat JFS gebruikt werd op systemen waar het niet gebruikte geheugen naar de vrije kon buffers gaan. Die JFS dan weer kon benutten. JFS is niet voor simpele eCS desktops, maar voor heel grote SMP bestandenservers met grote JFS caches ontworpen. Maar JFS werkt wel fijn op een moderne desktop PC die vaak betere specificaties heeft dan de servers waarvoor JFS ontworpen werd.
Op een vers geinstalleerd eCS systeem met 185 MiB RAM kwam ik de volgende standaardwaarden tegen.
[F:\]cachejfs SyncTime: 5 seconds MaxAge: 20 seconds BufferIdle: 4 seconds Cache Size: 23622 kbytes Min Free buffers: 118 ( 472 K) Max Free buffers: 236 ( 944 K) Lazy Write is enabled
De vrije JFS buffers zijn hier tussen de 472 en 944 K. Weliswaar meer dan de maximale 50 K van HPFS en FAT, maar toch weinig vergeleken met de 50 kiB buffers van de 2048 KiB HPFS cache.
Op een 2 GIB RAM systeem met een vooraf op 164000 KiB JFS cache zag ik dit.
[F:\]cachejfs SyncTime: 5 seconds MaxAge: 20 seconds BufferIdle: 4 seconds Cache Size: 164000 kbytes Min Free buffers: 820 ( 3280 K) Max Free buffers: 1640 ( 6560 K) Lazy Write is enabled
Blijkbaar is het maximale aantal vrije JFS buffers (Max Free buffers) standaard 1% van de in JFS.IFS /CacheSize:n opgegeven grootte in KiB. En is het minimale aantal JFS buffers 0,5% hiervan. Bij een buffer (PageFrame) grootte van 4 KiB gaat het om 2-4% van de cache. En als de JFS cache 12,5% (1/8) van het fysieke geheugen is zijn de JFS buffers tussen de 0,25 en 0,5% van het fysieke RAM. En dat is eigenlijk niet eens zo hoog.
Nu blijkt het aantal vrije buffers (cstats' nfreecbufs) op een rustig systeem veel hoger te zijn dan maxfree waarde.
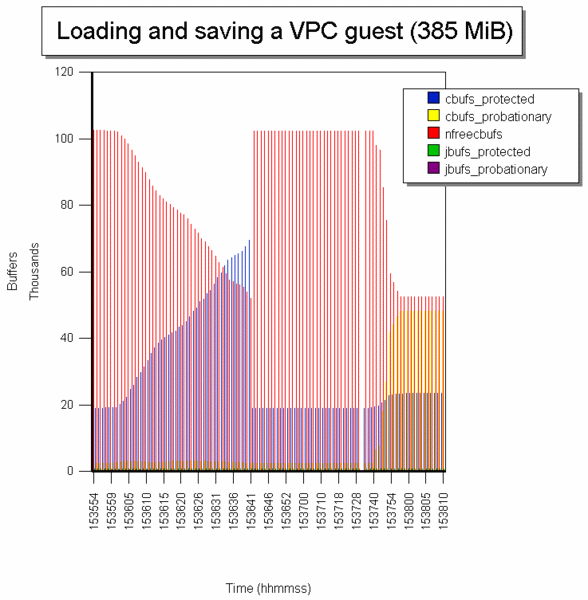 Het
onderstaande plaatje geeft de cache statistieken weer bij de volgende
acties:
Het
onderstaande plaatje geeft de cache statistieken weer bij de volgende
acties:
1). Een Windows XP snapshot laden.
2). Windows XP in VC draaien
3). En weer (lazy) opslaan
De Windows XP home snapshot had 385 Mib RAM en was opgeslagen in een vsv-bestand van 195 MB. De vhd-images waren 6278 MB groot.
Ctats werd om de 1 sec gedraaid. De uitvoer ging naar een cvs-bestand dat ingelezen werd door improv..
Nfreecbufs (rood) zijn het aantal vrije buffers. Ze zijn eerst ruim 100000 (bij een cachesize van 125000), maar nemen snel af als het geheugen van de gast PC geladen wordt. Het gaat ongeveer om 50000 buffers van 4 KiB, dus 200 MB.
De cbufs_protected nemen ondertussen met dezelfde aantallen toe. Ze bevatten de het vsv-bestand van 195 MB.
Als om 15:36:41 de gast PC geladen is, schieten de vrije buffers ineens weer omhoog en de cbufs_protected omlaag. Dit komt omdat de het vsv-bestand van 195 MB uit de cache verdwijnt.
De jbufs die directory- en bestandenlijsten (verg. de FAT tabel) bevatten blijven relatief gespaard.
Bij het afsluiten van de VPC (15:37:40) nemen de vrije buffers weer af. Opvallend is het hoge aantal cbufs_probationary (geel) die het vhd-bestand vertraagd wegschrijven. Ze zullen snel uit de cache verdwijnen (hier niet getoond) om voor vrije buffers plaats te maken. Daarna zal de situatie weer op die van begin gelijken.
Overigens zullen er in een situatie waar er meer programma's draaien minder vrije buffers beschikbaar zijn. Hieronder hadden Thunderbird en Firefox blijkbaar veel bestanden geopend.
De meeste bestanden zaten als cbufs_probationary (licht blauw) in de cache. Tijdens het laden van de gast (19:20:12) maakten die cbufs_probationary plaats voor cbufs_protected. En nadat de gast geladen was kwamen de 195 MB vrij. Hoewel de schijf aldoor groen was (Windows was aan het updaten e.d.) namen de cbufs maar weinig toe. Na het opslaan van de snapshot (even na 19:21:19) en het afsluiten van VPC stegen de cbuffers weer.
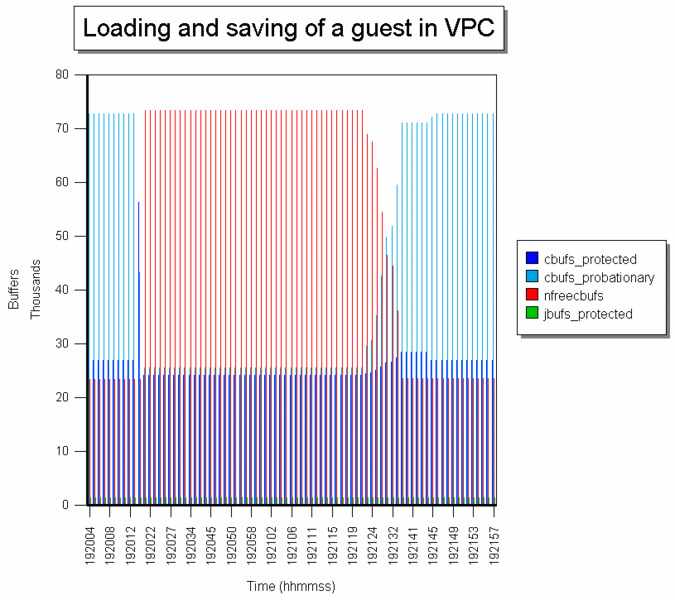
Hieronder
ziet u een diagram van bovenstaande situatie weer, maar dan met alle
gegevens van cstats:
Bedenk
dat cachesize en slruN constanten zijn.
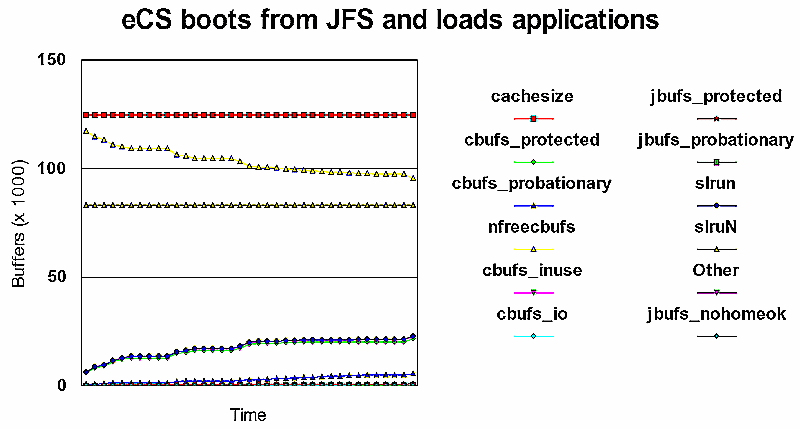
Tijdens het maken van een directory listing op een grote driekwart gevulde 200 GiB JFS schijf K, bleek dat ook een 400 MiB JFS cache vrijwel volledig met metadata (J_buffers) gevuld kon worden. Een treesize onder de WPS duurde uren.
De schijf bevatte zowel grote bestanden (VPC mirrors) als relatief kleine bestanden (dsync backups van eCS partities en een SmartCache). Maar het was vooral de cachedir van SmartCache met een half miljoen bestanden die JFS problemen gaf.
De SmartCache auteurs onderkennen dit probleem (http://scache.sourceforge.net/doc/ch-admins.html):
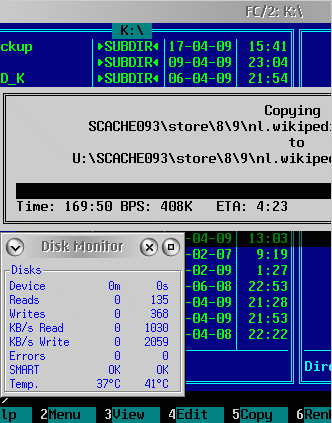
Om deze bewering na te gaan formatteerde ik schijf U als HPFS en kopieerde de SmartCache directory daar naar toe met FC/2. Na een reboot voerde ik een tree test onder HPFS386 uit. Daarna herhaalde ik het op de nu als 4 K standaard geformatteerde JFS partitie U: met steeds grotere JFS caches.
En wat bleek? JFS is zeker niet langzamer dan het doorgaans als snel beschouwde HPFS386, maar dit telt pas bij grotere (> 100 MIB) JFS caches.
De kopieeractie van JFS op K naar JFS op U duurde met 300-400 KBS bijna 3 uur (175 min) bij een CPU-use van (2-20%). Maar de werkelijke belasting was voor mijn gevoel veel hoger. De WPS voelde traag aan. Iets dat niet ervaar als FFMPEG met priority 1 100% CPU-Use veroorzaakt. Een hoge CPU-use zegt dus niet alles.
De statische cache was tijdens deze kopieeractie volledig bezet (slrun=slruN) en had meer c_buffers als j_buffers. Maar zeker meer j_buffers als gebruikelijk (en soms vrij zeldzame jbufs_io van 400 of meer) .
[multiboot|f:/]time cstats cachesize 100000 cbufs_protected 36946 hashsize 65536 cbufs_probationary 17683 nfreecbufs 14116 cbufs_inuse 0 minfree 8000 cbufs_io 1 maxfree 16000 jbufs_protected 29720 numiolru 0 jbufs_probationary 1524 slrun 66666 jbufs_inuse 0 slruN 66666 jbufs_io 0 Other 8 jbufs_nohomeok 2 real 0m0.160s user 0m0.170s sys 0m0.000s
Maar de timer van sh gaf aan dat CLI programma's als cstats nog redelijk snel werkten. De traagheid van PM en de WPS kan ik niet verklaren. Temeer omdat ik van HPFS had geboot en de WPS Desktop op een ram disk stond.
Tijdens de kopieeractie zag ik slechts een foutmelding:
De lijst van uitgebreide kenmerken heeft een onjuiste grootte. (255) SCACHE093\store\12\0\www.xwiki.com\xwiki\bin\download\Main\WebHome\.cac# [ Retry ] [ Skip ] [ Cancel ]
Met een Retry ging het voort.
 PM
Disk Monitor (dskmon10.zip)
hierboven suggereert dat het bijwerken van de metadata (EA's en
directorystructuren) aanzienlijk kan zijn. En dit wordt door de LW
cache in kernel modus gedaan. Dit kan verklaren waarom de WPS trager
aanvoelde.
PM
Disk Monitor (dskmon10.zip)
hierboven suggereert dat het bijwerken van de metadata (EA's en
directorystructuren) aanzienlijk kan zijn. En dit wordt door de LW
cache in kernel modus gedaan. Dit kan verklaren waarom de WPS trager
aanvoelde.
Opmerkelijk is dat de 1030 KB/s Read en 2059 KB/s write (twee keer zoveel!) tijdens het kopiëren van de SmartCache directory structuur duidelijk groter was dan de 400 KB/s transportsnelheid die FC/2 in hetzelfde beeld mat. Blijkbaar meet FC/2 alleen de pure bestandsoverdracht: in cstat termen de c_buffers.
Directories (formeel ook bestanden) hebben een bestandsgrootte van 0 en tellen dus voor FC/2 niet mee. Maar de SmartCache directory kenmerkte zich door uitzonderlijk veel directories en kleine bestanden. Zie: De eigenschappen van drives waarop de tree testen uitgevoerd werden. Die geven meer overhead op JFS, en die overhead moet ook mee.
Inderdaad geeft een kopieeractie van een enkel MPG bestand naar die schijf een totaal ander beeld. Zie de snapshot hiernaast. De WPS voelde hierbij niet traag aan. De Disk Monitor door KB/s Write van 16218 is hier weliswaar wat groter dan de KB/s Read van 15328, waarschijnlijk omdat ook typische JFS metadata als aanduidingen voor vrije blokken op U geschreven worden. Maar de 14 M door FC/2 bestandsoverdracht komt dicht in de buurt van iets op FC/2 achterlopende PM Disk Monitor die om de 5 seconden polde.
Het kopieren van het MPG bestand naar de al vrij bezette schijf begon met 19 M en eindigde met 14 M. PM Disk Monitor mat daarna nog een lazy write effect.
De eigenlijke test met het programma tree ging als volgt:
[F:\]bash [multiboot|f:/]cachejfs SyncTime: 5 seconds MaxAge: 20 seconds BufferIdle: 4 seconds Cache Size: 100000 kbytes Min Free buffers: 500 ( 2000 K) Max Free buffers: 1000 ( 4000 K) Lazy Write is enabled [multiboot|f:/]time tree i: >NULL real 1m2.480s user 1m2.480s sys 0m0.000s [multiboot|f:/]time tree i: >NULL real 0m17.050s user 0m17.050s sys 0m0.000s [multiboot|f:/]time tree u: >NULL real 8m54.300s user 8m54.300s sys 0m0.000s [multiboot|f:/]time tree u: >NULL real 9m54.270s user 9m54.270s sys 0m0.000s
De procedure werd steeds in dezelfde volgorde uitgevoerd na een verse reboot. Dit om gelijksoortige omstandigheden te creeren.
De testen werden uitgevoerd met de eCS standaard waarden IFS=F:\OS2\JFS.IFS /LW:5,20,4 /CACHE:XXX /AUTOCHECK:*
De uitvoer van tree.com (OS/2 Command Line Utilities version 2.2) werd naar device NULL gestuurd omdat ik niet geïnteresseerd was in de videoprestaties. Ik draaide gewoon PM met StarOffice en PM Disk Monitor 1.0. Ik was ook niet geïnteresseerd in kleine verschillen. Maar ik zorgde er wel voor dat de voor en achtergrondactiviteit het systeem minimaal belastte. Bij twijfel (een automatische WPS backup werd een keer opgestart) herhaalde ik de test en noteerde ik de laatste waarde.
Overigens zag ik bij herhaalde testen regelmatig schommelingen in de orde van 10%! En niet in de kortdurende testen op I, maar juist bij de langer durende testen op U waar tree 100% CPU use aangaf. Hiervoor was de thermal throttling van de processor verantwoordelijk.
De resultaten van de metingen staan in onderstaande tabel. De real waarden van bash built-in functie time werden omgerekend naar seconden De user tijd was meestal gelijk, maar soms enige ms kleiner dan real. Variaties in de orde van 10% kun je er niet mee verklaren. De door time opgeven sys tijd was altijd 0. Cache overhead kun je er dus niet mee meten.
|
cache (*1000 KiB) |
25 |
50 |
100 |
200 |
400 |
800 |
|---|---|---|---|---|---|---|
|
1e time tree u: |
3533 |
588 |
594 |
536 |
510 |
411 |
|
2e time tree u: |
3564 |
653 |
594 |
524 |
483 |
375 |
|
cpu- use |
8,00% |
2-100% |
2-100% |
2-100% |
2-100% |
2-100% |
|
1e time tree i: |
64 |
74 |
62 |
62 |
62 |
62 |
|
2e time tree i: |
62 |
61 |
17 |
16 |
16 |
16 |
|
cpu-use |
laag |
laag |
laag |
10-40% |
10-70% |
10-70% |
In dit overzicht heb ik metingen met nagenoeg dezelfde waarden weggelaten. Het gaat om JFS caches van 300, 500,600,700, 900 en 1000 MB. Het resultaat is een logaritmische tabel, die de trend beter laat zien.
Wat vertellen deze gegevens ons?
Zoals gezegd zag ik forse variaties in de duur van de tree test op U bij het herhaald meten onder op het gezicht identieke omstandigheden. Deze verschillen konden bij een 400 sec durende fill-test op U wel 40 seconden bedragen. En dat is 10%.
Ze waren niet met spontane WPS activiteit (een interactief systeem) te verklaren. In rust schommelt mijn CPU-use tussen de 2-5% en de paar procent variatie die dat geeft zou vooral in de korter durende testen zichtbaar moeten zijn. Maar die waren redelijk consequent. Bij langer durende testen zouden de effecten daarvan juist uitmiddelen.
De enige plausibele verklaring die ik heb, is dat bij de langdurig gecachte testen de CPU snelheid teveel varieerde. Dit omdat mijn snel te warm wordende Celeron vaak al na 20 seconde full speed al weer zo heet wordt (72 graden) dat hij op halve snelheid verder moet gaan om weer af te koelen. En als tree - dankzij een grote cache - voluit kon gaan (100% CPU-use), werd de processor te heet en halveerde het ACPI BIOS de kloksnelheid totdat de processor voldoende was afgekoeld.
Kortom, achteraf gezien was dit een slecht gekozen test systeem. Maar het geeft wel aan hoe het er in de echte wereld toegaat.
Situaties van hoge CPU-use kwamen veel voor. Voor zover ik met Watchcat (tijdens herhaalde sessies) kon nagaan was het enige programma met 99% cpu-use tree.com. En dat is een gunstig teken: het betekent dat tree voluit kon gaan met gecachte gegevens zonder op de trage schijf te hoeven wachten. PM Disk Monitor gaf bij 99% CPU-use aan dat de I/O laag was (bijv. 1-3 KB/s). En dat kan kloppen omdat de PM Disk Monitor (i.t.t. FC/2) de met succes gecachte I/O niet meet.
Verder had ik verwacht dat het herhalen van een tree opdracht sneller zou zijn dan de eerste keer, omdat er de tweede keer meer relevante gegevens (hier J_buffers) in de cache zouden zijn. Maar dat hoeft niet altijd het geval te zijn. Het hangt erg af van de grootte van de cache t.o.v. de grootte van de schijf en de verdeling van de bestanden op het bestandssysteem.
|
Eigenschappen van schijf U (10 GiB) volgens chkdsk |
|
|---|---|
|
33350908 kilobyte totale schijfruimte (100%). 21780 kilobyte in 10929 directory's (0,06 %). 23719828 kilobyte in 144192 gebruikersbestanden (71,1%). 69036 kilobyte voor uitgebreide kenmerken (0,2%). 88288 kilobyte voor gebruik door het systeem (0,3%)). 9495536 kilobyte beschikbaar voor gebruik (28,5%). |
10747452 kilobyte totale schijfruimte (100%) 136721 kilobyte in 138482 directory's (1,4%). 5849097 kilobyte in 504970 gebruikersbestanden (54,4%). 360 kilobyte voor uitgebreide kenmerken (0,0%). 313504 kilobyte voor gebruik door het systeem (2,9%). 4721212 kilobyte beschikbaar voor gebruik (43,9%). |
Op schijf I: van 32 GIB met vooral programma bestanden (gemiddeld 164,65 KiB/bestand) zie je de verwachte snelheidswinst (4x sneller) al met een 100 MIB JFS cache, maar op schijf U: met SmartCache ontbrak dit fenomeen.
De kleinere schijf U (10 GiB) werd gekenmerkt door 12,67 maal zoveel directories en 3,5 maal zoveel bestanden van gemiddeld maar 11,58 KiB groot. Hier viel de 2e ronde doorgaans trager uit. U ziet dat
Blijkbaar hebben de de gegevens die het laatst bij de eerste tree opdracht waren gebruikt (bijv. de opsomming van de directories x-z), weinig waarde voor het snel inlezen van de directories a-c waar de 2e tree opdracht weer mee begint. En waarom is de 2e ronde dan langzamer? Omdat de cache de 2e ronde met minder vrije buffers aan tree begint. Ik voerde tree test immers uit op pas gestart systeem. Daarnaast kan thermal throttling van de processor een rol spelen.
Vaak wordt beweert dat HPFS386 sneller is dan JFS. Dat kan kloppen voor relatief kleine caches (< 32 MiB) en op het netwerk, maar 50 MB JFS cache presteerde al beter dan een 128 MB HPFS386 cache op de tree test op U.
Tree onder HPFS386 (128000 KiB).
[multiboot|f:/]time tree u: > NULL real 15m5.520s (905,520 s) user 15m5.520s sys 0m0.000s Tree op K met JFS
eComStation 1.2 koos er voor om de JFS driver als volgt op te starten:
IFS=C:\OS2\JFS.IFS /LW:5,20,4 AUTOCHECK:*
Wat betekent dit? Het pad van de JFS.IFS driver is C:\OS2\JFS.IFS.
[F:\]cachejfs
SyncTime: 5 seconds
MaxAge: 20 seconds
BufferIdle: 4 seconds
Cache Size: 65536 kbytes
Min Free buffers: 327 ( 1308 K)
Max Free buffers: 655 ( 2620 K)
Lazy Write is enabledDe parameters /LW:5,20,4 zonder /CACHESIZE betekenen: Stel de lazy write cache in op de default van 64 MiB of 12,5 % van het fysieke geheugen, laat de synchronisatiedraad om de 5 seconden (Synctime) de meer dan 4 seconden (Bufferidle) ongewijzigd gebleven 'idle' buffers wegschrijven en laat hem uiterlijk na 20 seconden (MaxAge) ook recent veranderde cache inhoud naar de vaste schijf wegschrijven. De waarden voor de vrije buffers zijn relatief laag en dat betekent dat een eenmaal verzadigde cache niet meer zoveel vooruit kan lezen (maximaal 2620 K).
/AUTOCHECK:* betekent dat de logbestanden van alle (*) herkende JFS volumes gecontroleerd worden op fouten. Is een schrijfactie in het logbestand niet netjes met een COMMIT, dan zal er een snelle gerichte chkdsk controle op de recente (MAXAGE) wijzigingen in de logbestanden volgen en als dat de zaak niet oplost, zal een volledige chkdsk van het JFS bestandssysteem volgen (tijdrovend).
Waarom zijn de eCS cache synchronisatie waarden (5, 20, 4) veel lager dan de standaard [/LW:64,256,8] OS/2 4.5 Warp Server instellingen van IBM? Omdat in de OS/2 nieuwsgroepen gerapporteerd werd dat de default JFS cache instellingen van de IBM Warp 4.5 LAN Server teveel gepaard gingen met schrijffouten. Terwijl een IFS=C:\OS2\JFS.IFS /LW:5,20,4 AUTOCHECK:* het in de dynamische eCS desktoppraktijk veel beter deed. Hoe kon dit gebeuren?
Om te beginnen werd de OS/2 versie van JFS ontworpen voor IBM Warp 4.5 LAN servers. JFS was ook afkomstig van AIX. Een eenmaal geladen OS/2 4.5 Warp bestandenserver die meerdere LAN clients bedient, zal qua processortijd relatief laag belast worden. De server zal weliswaar veel bestanden serveren (data en en wellicht ook applicaties), maar omdat de geopende tekstbestanden maar weinig in de tijd veranderen werkt een lang synchronisatie-interval goed. Als 1024 typisten ieder een afzonderlijk tekstbestand van 100 KiB bewerken, dan volstaat een cache van 100 MiB voor 1024 gebruikers. En zeg een paar honderd MiB voor de applicaties. Grote en snelle bestandswijzigingen zullen hierbij niet snel optreden. De door de LAN clients benaderde bestanden kunnen in het cache-geheugen vastgehouden totdat ze - typisch een voor een - door de clienten afgesloten worden. In die relatief statische situatie werkt een langzaam synchroniserende cache (/LW:64,256,8) met goed 96-98% geheugen voor de cache en 2-4% vrije buffers goed.
Problemen met deze statische JFS cacheinstellingen ontstaan pas als er in korte tijd veel gegevens doorgevoerd moeten worden. Tijdens grote XCOPY opdrachten en netwerk benchmarks wordt de inhoud van de cache in korte tijd ververst. En dan komt een cache met een verversingsinterval van 64 seconden en maar 2-4% vrije buffers snel in de problemen. Want er zijn te weinig synchronisatieronden en vrije buffers om de wijzigingen bij te houden.
Dit geldt ook voor de dynamisch eCS desktop waarop u in korte tijd meerdere I/0 intensieve programma's als mencoder, mplayer, VirtualBox, VirtualPC, Java, Mozilla en Firefox tegelijkertijd kunt laden. Al die gegevens moeten door de JFS cache gaan. En vooral als er razendsnel heel veel nieuwe gegevens aangemaakt worden, loopt een traag synchroniserende JFS cache met een gering aantal vrije buffers een groot gevaar om snel vast te lopen.
Een voorbeeld met mencoder kan dit verduidelijken.
Stel dat mencoder een 1 GiB bestand inleest en een gewijzigde versie ervan op JFS aanmaakt. Dank zij de snelle read ahead JFS cache is de volgende indexatieopdracht binnen twee minuten voltooid (120 s).
MENCODER A.MPG -forceidx -oac copy -ovc copy -of mpeg -o B.MPG
De mencoder uitvoer geeft aan dat het bestand B.MPG 1080 MB groot is, al op 45% zit en binnen een minuut klaar zal zijn..
Pos: 682.2s 17055f (45%) 459.20fps Trem: 0min 1080mb A-V:0.012 [5593:384]
De vrije buffers zullen al na een paar seconden op raken en tijdens de eerstvolgende synchronsatieronde (pas na 64 sec, dus na aanmaak van 500 MIB) zal een 400 MiB /LW cache zich vrijwel compleet moeten verversen. Dan moeten in korte tijd honderden megabytes naar de schijf geschreven worden door een cache die hier niet voor is ingesteld. Dit JFS cache tuning probleem vormt denk ik de basis van de deadlocks die na xcopy opdrachten zijn beschreven (apar.txt).
Ik kwam deze problemen ook tegen bij combinaties van processor en schijfintensieve opdrachten. Bijv. als EmperoarTV, VPC, mencoder en een backup tegelijkertijd liepen. De WPS reageerde opeens typisch niet meer en het groene lampje van de schijf ging uit. In dat laatste geval (een echte deadlock) kon alleen een harde rest de systeem latten herstarten. Maar probeer het natuurlijk altijd eerst met CAD het systeem af te sluiten.
De kans op dergelijke vastlopers is hoger bij een grotere JFS cache (> 200 MIB), langere synchronisatietijden en bij een gering aantal vrije buffers. En natuurlijk wil de ironie dat we op snelle PC's met veel geheugen en hoge bandbreedte eerder tegen deze limieten aanlopen. Bedenk dat de servers waarvoor IBM Warp 4.5 server (1998) was ontworpen veel minder krachtig waren dan een huidige desktop PC.
Op desktop systemen waar in hoog tempo veel bestanden gecreëerd (kopiëren) of veranderd (schijf images) worden, kan de cache beter met de kortere synchronisatietijden (IFS=F:\OS2\JFS.IFS /LW:5,20,4) werken. En daarnaast raad ik u aan om bij grote (> 200 MiB) JFS caches het aantal vrije buffers te verhogen.
Wat voor u de beste cache waarden zijn hangt natuurlijk af van wat u op JFS doet. En over welke bronnen (processor, geheugen, schijven) u beschikt,
Maar ik ben er inmiddels wel van overtuigd dat de standaard JFS cache grootte van 12,5% van het beschikbare geheugen doorgaans veel te krap bemeten is. Zo'n kleine cache doet JFS en eCS tekort. Dus allereerst bespreek ik het onderwerp cache grootte.
Doorgaans neemt de effectiviteit van een cache toe naarmate hij groter wordt. Hoe groter de cache, des te meer het aantal cache hits/tijdseenheid. Maar op een zeker moment neemt de effectiviteit van een grotere cache weer af omdat: 1) een grotere cache de recent meest opgevraagde buffers (schijfgegevens) al bevat en vervolgens alleen maar meer gevuld wordt met steeds minder frequent opgevraagde gegevens (een statistisch fenomeen) en 2) een grotere cache meer overhead geeft om de cache-inhoud tijdens een synchronisatieronde actueel te houden (een cache-management probleem).
Om die redenen wordt op grote schijven een cache-hit rate van 90% vaak als optimaal beschouwd. Om de 95% te halen moet de cache misschien wel 2 of drie maal zo groot zijn, met navenante cache overhead en negatieve effecten op het vrije geheugen. En om een 99% cache-hit op een file server te halen moet misschien wel 30-50% van het bestandssysteem gebufferd zijn. Waarbij vaak nog de meeste winst te behalen valt uit het cachen van de veelvuldig benaderde directorystructuren in of nabij het root bestandssysteem.
Dus als gebruiker A c:\home\a\docs\a.doc inleest en vlot daarna gebruiker B c:\home\a\docs\b.doc inleest, worden de directories c, home in ieder geval al twee keer benaderd en komen dus in de beschermde J_buffers terecht (waar ze meteen ook van nut zullen zijn voor gebruikers C, D. ..) en worden de directories a en b en de bestanden a.doc en b.doc als probational buffers gecached. En worden ze vrij snel daarna (voordat de vrije buffers opraken) opnieuw via Ctrl-S of Crl-P benaderd, dan komen ze in de beschermde buffers terecht.
Dat hoeft in de OS/2 praktijk niet altijd zo te zijn blijkens de uitvoer van CACHE386.EXE /STATS:D die hier de statistieken sinds het booten weergeeft van een 128 MB HPFS386 cache die de OS/2 boot en 4 GiB HPFS data partities bediend:
CACHE386 Statistics Read Requests: 93025353 Disk Reads: 430213 Cache Hit Rate (Reads): 99% Cache Reads: 92595140 Write Requests: 860244 Disk Writes: 35712 Cache Hit Rate (Writes): 95% Lazy Writes: 824532 Hot Fixes: 0
Na een reset (cache386 /clear) geeft de HPFS386 cache een nog rooskleuriger beeld.
CACHE386 Statistics Read Requests: 2642 Disk Reads: 8 Cache Hit Rate (Reads): 99% Cache Reads: 2634 Write Requests: 6 Disk Writes: 0 Cache Hit Rate (Writes): 100% Lazy Writes: 6 Hot Fixes: 0
Maar vlak na de op de reset volgende dsync operatie (HPFS > JFS) op de 4 GiB datapartitie zijn de statistieken al weer minder gunstig.
CACHE386 Statistics Read Requests: 423451 Disk Reads: 224032 Cache Hit Rate (Reads): 47% Cache Reads: 199419 Write Requests: 12371 Disk Writes: 22 Cache Hit Rate (Writes): 99% Lazy Writes: 12349 Hot Fixes: 0
Dit komt doordat vrijwel alle door dsync opgevraagde directories nog niet eerder opgevraagd zijn. De Cache Hit Rate statistieken zouden nog meer achteruit gaan als u er ook 8 GB MPEG bestanden mee opneemt en converteert. Maar die klus kan alleen aan JFS worden uitbesteedt (HPFS heeft een 2 GIB limiet).
De relatie tussen cache grootte en effectiviteit is statistisch gezien een semi-logaritmische functie. Een y die steeds langzamer ten opzichte van de cachegrootte op x-as toeneemt naar oneindig. Maar omdat de hoeveelheid werkgeheugen (werkgeheugen minus cache grootte) en ook de de virtuele adresruimte eindig zijn buigt de curve op een zeker moment steeds sneller af naar beneden om bij het punt (werkgeheugen minus cache grootte = working set) een halt te houden. Want dan loopt het systeem vast. Als de cache van de minimaal benodigde hoeveelheid systeemgeheugen (de working set van het systeem) afknabbelt betekent dat meer swapping. En die swapping wordt onder OS/2 niet gecached.
De voor servers bedoelde HPFS386 cache gebruikte standaard al 20% van het fysieke geheugen in een tijd dat fysiek geheugen duur en krap bemeten was. Maar OS/2 werd er veel sneller door. Waarschijnlijk al op 16 en 32 MiB RAM systemen met een 25-100 MHz processor.
Maar het voor AIX servers ontworpen JFS heeft veel meer resources nodig dan HPFS. Het is intern 64 bits en moet met veel grotere bestanden en partities kunnen omgaan. En ook al doet het dat niet op een standaard eCS bootpartitie, die aanbieden van die mogelijkheid geeft wel meer overhead. JFS slaat de inhoud en namen van databestanden en directories ook kwalitatief beter, maar in bits en bytes gerekend minder efficiënt op. Het onder alle talen (codepages) dezelfde tekens opleverende Unicode UTF-8 kost 1-4 bytes per teken, maar een klassieke tekentabel als CP 850 kost maar 1 byte per teken. Gelukkig is het verlies aan vrije ruimte minimaal omdat UTF-8 de meest voorkomende ANSI tekens als 1 byte (8 bits) codeert.
Alleen al om die reden heeft bootable JFS meer overhead (geheugen, cpu-use) nodig om eCS te booten dan HPFS. Maar als die resources beschikbaar zijn (tegenwoordig bijna standaard) zal bootable JFS sneller zijn dan HPFS. Zeker met de grote programma's als OpenOffice en Mozilla.
In de moderne eCS praktijk moet de JFS cache grotere bestanden, grote partities en en ingewikkelder diectorieboomstructuren cachen. Daar is het (i.i.t. HPPFS en zeker vFAT) prima op berekend, maar om het goed te doen heeft JFS weel meer geheugen nodig. Om die reden is de JFS cache standaard omvang van 12,5 % van het fysieke geheugen tot een maximum van 64 MiB meestal veel te krap bemeten.
Een minimaal eCS systeem met 32 MiB RAM dat nog net van diskette te installeren is, krijgt een 4 MiB JFS cache. Bij een 48 MiB RAM eCS systeem (deze boot al van CD) is dat een 6 MiB JFS cache. En een 64 MiB RAM systeem krijgt een JFS cache van 8 MiB.
Maar er is minimaal een 20 MiB JFS cache nodig om nog enigszins met JFS te kunnen werken! En op tientallen of honderden gigabyte grote schijven met veel mappen en kleine bestanden moet de JFS cache veel groter zijn. Anders zal alleen al een directory listing erg lang duren.
Op systemen met minder dan 64 MiB RAM kunt u beter alleen HPFS installeren. HPFS is ontworpen voor systemen van 4 tot 32 MiB geheugen in een tijd dat men schijven nog in megabytes mat. En processors nog onder de 100 MHZ klokten. JFS is op dergelijke systemen misschien nog wel bruikbaar, maar minder efficient dan HPFS. Gebruik JFS op dergelijke verouderde systemen dus alleen als u het echt nodig hebt. Maar niet voor 1-2 GiB partities waar JFS u geen voordeel biedt.
Een systeem met 128 MiB RAM levert standaard een 16 MiB JFS cache op. Dat is op een snelle schijf werkbaar, maar ik zou er liever een 32 MiB of 48 MiB JFS cache van maken, En zo nodig geheugen uitbreiden. eCS zal ervan profiteren. Want met Lazy Commit (MEMMAN=SWAP, PROTECT) kan OS/2 op zo'n systeem iedere bit optimaal gebruiken, terwijl de 32 MiB JFS cache meteen na het booten van JFS al verzadigd zal zijn.
In het algemeen zou ik de JFS cache niet beneden de 32 MiB willen instellen. En zie ik de maximale 64 MiB meer als een goed werkbare waarde voor een systeem met 256 MiB RAM dat standaard maar 32 MiB krijgt. Op een systeem van 512 MiB RAM dat met een JFS cache van 64 MiB opstart zou ik minimaal voor een (25%) 128 MiB JFS cache gaan. Op mijn 1 GB laptop werk ik met tevredenheid met een 256 MiB cache en mijn 2 GiB eCS PC heeft een 512 MiB JFS cache. Waarbij ik vaak meer dan een gigabyte vrij geheugen over houdt.
Op alle JFS systemen (AIX, Linux en OS/2) die honderden gigabytes aan data bevatten kunt u het best de JFS cache zo hoog instellen als uw vrije geheugen doorgaans toelaat.
JFS is ontworpen voor gigabyte tot terabyte grote schijven. Dat zijn de partities die HPFS(386) in theorie tot 64 GiG aankon, maar waar HPFS nooit serieus op werd beproefd. Want toen die schijven er kwamen verkoos Microsoft het loggende NTFS van Windows NT boven het HPFS van NT en MS Lan Manager. Omdat de schijfcontroles (zoekacties naar fouten in het bestandssysteem) op HPFS urenlang konden duurden.
Met NTFS en JFS die alle recent uitgevoerde (transaction committed) veranderingen in de metadata (bestandsstructuur) in een apart logbestand bijhielden, kwam daar verandering in. Want na een crash hoefde de chkdsk alleen maar het logbestand (bij JFS 0,4% van de partitiegrootte) te onderzoeken om de bestandsstructuur van voor de crash te kunnen herstellen.
Maar een snelle foutopsporing via een logbestand van recente transacties betekent niet dat zoekacties op JFS sneller zijn. Het logbestand wordt hiervoor immers niet geraadpleegd. Alleen de cache wordt gebruikt. En de directories met bestandsinformatie die niet in de cache zitten, moet via de schijf in de cache worden geladen. En dat zal dus weer langer duren. Maar niet zolang als bij een chkdsk, want gelukkig worden de directorystructuren gecached. Maar dat heeft ook weer een prijs, omdat dan de bestanden uit de cache geknikkerd worden.
JFS zal om alleen maar de omvangrijke "FAT tabel" van een groot JFS volume gedeeltelijk in de j-buffers te laden veel zo niet alle eerder gecachete data uit zijn buffers moeten verwijderen. En op een simpel bootable eCS partitie van minder dan een GiB gooit een zoekactie een 32 MiB cachetabel al overhoop.
Onderstaande voorbeelden illustreren dit.
|
De kwetsbaarheid van een 32 MiN JFS cache. |
Op een eCS systeem met 256 RAM en bootable JFS is de cache 32 MiB. Maar het systeem heeft na het opstarten van de netwerkverbindingen nog 151 MB vrij. Na het opstarten van Firefox (30 MiB met lazy commit!) ) is er nog 122 MB vrij. Geheugengebrek is er dus niet. Maar de cache is al volledig verzadigd. De vrije buffers zijn minimaal en het merendeel van de buffers is protected. [C:\]cstats cachesize 8180 cbufs_protected 4902 hashsize 4096 cbufs_probationary 2467 nfreecbufs 209 cbufs_inuse 0 minfree 163 cbufs_io 0 maxfree 327 jbufs_protected 547 numiolru 0 jbufs_probationary 48 slrun 5449 jbufs_inuse 0 slruN 5452 jbufs_io 0 Other 3 jbufs_nohomeok 4 Maar na het zoeken in FC/2 naar tcpstart.cmd op C: zijn vrijwel alle protected c_buffers verdwenen! [C:\]cstats cachesize 8180 cbufs_protected 376 hashsize 4096 cbufs_probationary 122 nfreecbufs 6094 cbufs_inuse 0 minfree 163 cbufs_io 0 maxfree 327 jbufs_protected 1559 numiolru 0 jbufs_probationary 26 slrun 1935 jbufs_inuse 0 slruN 5452 jbufs_io 0 Other 3 jbufs_nohomeok De recente cache hits betroffen dus niet de bestanden (c-buffers), maar de metadata (j_buffers). Die zijn nu in de cache geladen. En cache- missers zullen dus onvermijdelijk optreden als u weer van Mozilla gebruik gaat maken. |
|
Treesize op een 200 GiB partitie kan uren duren |
Het uitvoeren van een Treesize op mijn 200 GIB grote JFS backup schijf kan uren duren. Zelfs een 500 MiB JFS cache heeft er moeite mee. En anders wel de WPS: Want volgens shmemmon had ik na een uur treesize (!) op zo'n schijf nog maar 69 MB shared memory over. En dat ligt niet aan JFS die zijn J-buffers in de virtuele systeemruimte mapt, maar aan de WPS die zijn directory listings graag met andere programma's deelt. Ik sloot treesize en Mozilla via Top af en de WPS kwam alsnog te voorschijn. Vandaar dat ik dit nog noteren kan. |
|
En kan OS/2 verwarren. |
Onderschat de capaciteit van het hybride 32-64 bit JFS niet. JFS kan via de extern 32 bits opererende (maar intern met veel meer bits werkende) kernel meer data aanleveren dan een 16/32 hybride bits OS/2 CLI en WPS ooit aankan. HPFS is nooit serieus op 64 GIB schijven getest, en dus zijn de meeste OS/2 CLI, PM en WPS programma's er ook niet op getest. We moeten dus serieus rekening houden met "out of memory errors" die met grote schijven te maken hebben! |
Ik vroeg me af hoe een JFS cache bezet zou zijn nadat eCS van bootable JFS gestart was.
 Ik
startte eCS 2.0 RC4 op mijn laptop op met een cache van
respectievelijk 32000 ,64000, 96000 en 128000 KiB en mat de
cachestats via een als eerste in startup.cmd gelanceerd script (met
runas wil rexx niet starten).
Ik
startte eCS 2.0 RC4 op mijn laptop op met een cache van
respectievelijk 32000 ,64000, 96000 en 128000 KiB en mat de
cachestats via een als eerste in startup.cmd gelanceerd script (met
runas wil rexx niet starten).
Een 32 MB cache heeft vrijwel meteen na het starten van startup.cmd al geen vrije buffers (geel) meer. De slrun is bij de tweede meting al maximaal (SlruN van 21 MB). De cache is dus al na 10 seconden na het starten van startup.cmd verzadigd. Om iets nieuws te laden moet de cache oude gegevens verwijderen. Dat kost meer tijd en gaat ten koste van de cache hit rate.
Een 64 MB cache hield meer vrije buffers (geel) over. Verzadiging trad dus niet op. Na ongeveer 60 seconden bereikte de slrun waarde slruN (hier 43 MB). 43 MB werd dus duurzaam gecachet en 21 MiB was voorlopig of vrij.
Een 96 MB cache heeft een slruN waarde van 64 MB. Bij de 128 cache is deze 85 MB (groen). Maar blauwe deel dat de slrun aangaf was in beide gevallen kleiner.
Wat opvalt is dat een 64 MiB JFS al vrij snel nadat eCS van JFS geboot is,
Als u op deze schijf een zoekactie zou uitvoeren, dan zouden er nog maar weinig bestanden worden gecached.
Deze bewering testte ik onder VPC.
De waarde cachesize is de som van de variabele waarden nfreecbufs, Other, cbufs_protected, cbufs_probationary, cbufs_inuse, cbufs_io, jbufs_protected, jbufs_probationary, jbufs_inuse, jbufs_io en jbufs_nohomeok. Oftewel: als er voor een actuele gecachte lazy write schrijfactie cbufs_protected nodig zijn, gaat dat ten koste van andere buffers. In de eerste instantie van de vrije (nfreecbufs) buffers, maar als die op zijn zoals in hte voorbeeld hierboven worden cbufs_probationary buffers vrijgemaakt.
De hele OS/2 JFS cache (cachesize) kan daarom grofweg ingedeeld worden in twee secties:
1). Een statisch (protected) deel dat in cstats door de waarde slrun (=cbufs_protected + jbufs_protected) aangegeven wordt en maximaal 2/3 van de cache kan zijn (de niet instelbare waarde van waarde van slruN).
2). En een dynamisch deel (cachesize - slrun) dat minimaal 1/3 van de cache moet zijn (cachesize - slruN), maar dat op pas opgestart en/of weer heel dynamisch geworden systeem veel meer buffers bevat . In dit deel zijn de buffers niet beschermd (protected) maar voorlopig (probational: in een proefperiode) aangesteld. En daarnaast bevat het buffers die nog met met I/O bezig zijn.
Op een optimaal voor een bestandenserver ingestelde JFS cache zou slrun uiteindelijk slruN moeten benaderen. Oftewel een maximaal aantal bestanden en directory ingangen zou beschermd moeten zijn tegen acute noden. Maar op een te kleine JFS cache zullen de acuut benodigde recente buffers net als bij de HPFS cache de oude garde verdrijven. Gewoon omdat er te weinig vrije en probationary buffers beschikbaar zijn. Dat is nuttig want omdat je vooral wilt dat de actuele I/O gebufferd is. Maar het betekent ook dat de eerder protected data even later opnieuw van de trage vaste schijf gelezen moet worden.
JFS bevat resistentie tegen fragmentatie. Maar fragmentatie komt desalniettemin wel voor.
U kunt de mate van fragmentatie van station I: opvragen (/question) met:
[F:\]defragfs /q i: Totaal aantal toewijzingsgroepen: 128. 15 toewijzingsgroepen zijn overgeslagen - volledig vrijgegeven. 25 toewijzingsgroepen zijn overgeslagen - te weinig vrije blokken. 1 toewijzingsgroepen zijn overgeslagen - bevat een te grote aaneengesloten beschikbare ruimte. 87 toewijzingsgroepen komen in aanmerking voor defragmentering. Gemiddeld aantal vrijgegeven verwerkingen in toewijzingsgroepen die in aanmerking komen: 657.
Met de opdracht DEFRAGFS [schijf]: kunt u JFS volumes defragmenteren. De opdracht werkt meestal ook op een bestandssysteem met geopende bestanden.
[F:\]defragfs i: Station i: wordt gedefragmenteerd. Even geduld a.u.b. Totaal aantal toewijzingsgroepen: 128. 15 toewijzingsgroepen zijn overgeslagen - volledig vrijgegeven. 25 toewijzingsgroepen zijn overgeslagen - te weinig vrije blokken. 1 toewijzingsgroepen zijn overgeslagen - bevat een te grote aaneengesloten beschikbare ruimte. 87 toewijzingsgroepen komen in aanmerking voor defragmentering. DEFRAGFS is zonder problemen voltooid. Totaal aantal toewijzingsgroepen: 128. 15 toewijzingsgroepen zijn overgeslagen - volledig vrijgegeven. 25 toewijzingsgroepen zijn overgeslagen - te weinig vrije blokken. 1 toewijzingsgroepen zijn overgeslagen - bevat een te grote aaneengesloten beschikbare ruimte. 87 toewijzingsgroepen zijn gedefragmenteerd. Gemiddeld aantal vrijgegeven verwerkingen in toewijzingsgroepen die in aanmerking komen: 585.
Soms werkt het niet :
[F:\DESKTOP]defragfs n: Defragmenting drive n:. Please wait. SYS1808: The process has stopped. The software diagnostic code (exception code) is 0005.
Dit station N: was via NFS als /home onder Linux gemount. Maar een tweede poging lukt vaak wel.
Let op: De auteur van "JRescuer for JFS", Pavel Shtemenko beschouwt het defragmenteren van JFS gevaarlijk.
Het aanhouden van voldoende vrije ruimte op de schijf (15%) biedt waarschijnlijk de beste garantie tegen fragmentatie.
De meeste bestandssystemen verdelen de schijf op in clusters. IBM spreekt van blokken. Deze wordt er tijdens het formatteren met een bepaalde grootte ingebracht (type: help format):
FORMAT [drive]: /FS:JFS /BS:blocksize
Onder OS/2 zijn blokgroottes van 512, 1024, 2048 or 4096 bytes toegestaan. Een waarde van 512 bytes is even groot als de kleinste eenheid van de vaste schijf (sectorgrootte). Dit is de blocksize van HPFS, welke zeer geschikt is voor een bootpartitie met de OS/2 WPS desktop en zijn kleine en EA-rijke bestanden erop. Maar als de /BS parameter weggelaten wordt gaat een FORMAT /FS:JFS uit van een blokgrootte van 4096 bytes (4 KiB). Ten tijde van mijn allereerste schrijven werden alleen blokgroottes van 4 KiB door JFS voor Linux ondersteund.
Het lezen, schijven en bijhouden van de bestanden op het bestandssysteem gaat sneller als er minder blokken hoeven te worden benaderd. Maar te grote blokken (clusters) leveren verspilling van vaste schijfruimte op. Dit speelt vooral op grote (1-2 GiB FAT) partities met clusters tot 32 kB (cluster). Microsofts FAT32 bracht hier verbetering in.
Bij de standaard clustergrootte van 4 kb (FAT32, JFS voor Linux) neemt ieder bestand minimaal 4096 bytes in beslag. Gemiddeld worden er dus 4096/2 is 2048 bytes per bestand verspilt. Dat is 8 maal zo veel als bij HPFS die maar een blokgrootte van 512 bytes heeft. Houdt hier rekening mee als u partities met veel kleine bestanden (mail, caches) naar JFS omzet. En bedenk dat HPFS veel zuiniger met uitgebreide attributen omspringt dan JFS. JFS slaat de 64 kb OS/2 EAs op in een apart blok op. Dus ook een uitgebreid attribuut van maar 1 byte groot neemt 4 KiB extra vaste schijf ruimte in. Onder HPFS zou u dit niet opmerken.
Hoeveel schijfruimte een kleinere blokgrootte u oplevert kunt u op het FAT bestandssysteem aan de hand van het aantal bestanden berekenen. De verspilde ruimte (slack) is de helft van blokgrootte maal het aantal bestanden. Maar voor JFS gaat deze vlieger niet op. Het is een heel ander bestandssysteem. Het gaat ook anders met de uitgebreide attributen om.
Informatie over het bestandssysteem krijgt u met CHKDSK [volume:]
J:\>chkdsk
The current hard disk drive is: J:
The type of file system for the disk is JFS.
The JFS file system program has been started.
CHKDSK File system is currently mounted.
JFS0138: CHKDSK Checking a mounted file system does not produce dependable results.
CHKDSK Block size in bytes: 4096
CHKDSK File system size in blocks: 1022127
CHKDSK *Phase 1 - Check Blocks, Files/Directories, and Directory Entries
CHKDSK *Phase 2 - Count Links
CHKDSK *Phase 3 - Rescan for Duplicate Blocks and Verify Directory Tree
CHKDSK *Phase 4 - Report Problems
CHKDSK *Phase 7 - Verify File/Directory Allocation Maps
CHKDSK *Phase 8 - Verify Disk Allocation Maps
CHKDSK Incorrect data detected in disk allocation structures.
4088508 kilobytes total disk space.
4065 kilobytes are in 1666 directories.
2834552 kilobytes are in 38640 user files.
116608 kilobytes are in extended attributes.
26701 kilobytes are reserved for system use.
1108052 kilobytes are available for use.
JFS0138: CHKDSK Checking a mounted file system does not produce dependable
results.
CHKDSK File system is dirty.
CHKDSK File system is dirty but is marked clean. In its present state, the results of accessing J: (except by this utility) are undefined.
..|......
J:\>Hier gaat het om 38640 bestanden in 1666 directories. Aangezien ook mappen bestanden vertegenwoordigen tel ik 38640 en 1666 bij elkaar op: de som ervan is 40306. De gemiddelde slack is dus 40306 maal 4/2 KiB = 2 KiB per bestand. Dat is hier 80612 KiB of 78,72 MiB.
Backup maken:
Y:\>xcopy j:\*.* y:\j\*.* /h/o/t/s/e/r/v
Met een blocksize van 1024 bytes formatteren.
Y:\>format j: /fs:jfs /bs:1024
Backup terugzetten:
Y:\>xcopy y:\j\*.* j:\*.* /h/o/t/s/e/r/v ..... 38640 file(s) copied.
Wat levert het op?
Y:\>chkdsk j:
The current hard disk drive is: J:
The type of file system for the disk is JFS.
The JFS file system program has been started.
CHKDSK File system is currently mounted.
JFS0138: CHKDSK Checking a mounted file system does not produce dependable results.
CHKDSK Block size in bytes: 1024
CHKDSK File system size in blocks: 4088511
CHKDSK *Phase 1 - Check Blocks, Files/Directories, and Directory Entries
CHKDSK *Phase 2 - Count Links
CHKDSK *Phase 3 - Rescan for Duplicate Blocks and Verify Directory Tree
CHKDSK *Phase 4 - Report Problems
CHKDSK *Phase 7 - Verify File/Directory Allocation Maps
CHKDSK *Phase 8 - Verify Disk Allocation Maps
CHKDSK Incorrect data detected in disk allocation structures.
4088511 kilobytes total disk space.
2782 kilobytes are in 1666 directories.
2778148 kilobytes are in 38640 user files.
41989 kilobytes are in extended attributes.
25349 kilobytes are reserved for system use.
1245807 kilobytes are available for use.
JFS0138: CHKDSK Checking a mounted file system does not produce dependable results.
CHKDSK File system is dirty.
CHKDSK File system is dirty but is marked clean. In its present state, the results of accessing j: (except by this utility) are undefined.
.......|.Wat levert het aan vrije ruimte op? 1245807 minus 1108052 = 137755 kilobytes of 134,526 megabytes. Dat is dus meer dan berekend werd vanuit de bestandsgroottes.
Het verschil zit hem in de uitgebreide attributen, die net als mappen als afzonderlijke bestanden worden opgeslagen. Daarom is x in "x kilobytes are in extended attributes" ook steeds een meervoud (bijv. hier vierfout) van de blokgrootte.
4080476 kilobytes total disk space.
9276 kilobytes are in 3905 directories.
2630439 kilobytes are in 73439 user files.
12692 kilobytes are in extended attributes.
39133 kilobytes are reserved for system use.
1407488 kilobytes are available for use.Nog een test. De bestanden van J (JFS met blokgrootte van 512 bytes) worden met dsync naar D (HPFS) overgebracht. Dsync zorgt voor een identieke synchronisatie.
Wat geeft een chkdsk J (JFS)?
[F:\]chkdsk j: /f
Het actieve station met vaste schijf is: J:
Het type bestandssysteem voor de schijf is JFS.
Bestandssysteem JFS is gestart.
CHKDSK - Blokgrootte in bytes: 512
....
4088511 kilobyte totale schijfruimte
2673 kilobyte in 1782 directory's.
3306703 kilobyte in 25917 gebruikersbestanden.
25940 kilobyte voor uitgebreide kenmerken.
273255 kilobyte voor gebruik door het systeem.
485286 kilobyte beschikbaar voor gebruik.
...
CHKDSK - LVM meldt 0 beschadigde blokken. Hiervan zijn er 0
overgebracht naar de JFS-lijst van beschadigde blokken.Wat geeft een chkdsk D (HPFS)?
[F:\]chkdsk d: /f
Het actieve station met vaste schijf is: D:
Het type bestandssysteem voor de schijf is HPFS.
Bestandssysteem HPFS is gestart.
CHKDSK is searching for lost data.
CHKDSK has searched 100% of the disk.
4096542 kilobytes total disk space.
5995 kilobytes are in 1782 directories.
3306663 kilobytes are in 25917 user files.
22957 kilobytes are in extended attributes.
6062 kilobytes are reserved for system use.
754865 kilobytes are available for use.HPFS springt duidelijk zuiniger met de OS/2 data (bestanden en hun EAs) om: na een dsync operatie bevatten de beide partities evenveel bestanden, maar JFS heeft 4088511 - 485286= 3603225 kilobytes gebruikt en HPFS 4096542 - 754865= 3341677 kilobytes. JFS gebruikt 8% (3603225/ 3341677= 1,08) meer schijfruimte als HPFS. Dit komt deels door het minder efficiënt opslaan van de uitgebreide attributen in aparte bestanden door JFS. Daarnaast gebruikt een 4 GB 32 bits HPFS schijf minder systeem overhead (6062/4096542= 0,148%) dan een 4 GB 64 bits JFS systeem ( 27325/4088511 = 0,67%). Maar dit is te verwachten bij een intern 64 bits werkend de I/O transacties loggend bestandssysteem.
Conclusie: kleine databestanden met uitgebreide attributen kon u op HPFS goed kwijt. Met een blokgrootte van 512 bytes worden uitgebreide attributen ook efficiënt door JFS opgeslagen. Maar het nadeel van de 512 bytes blokgrootte is dat u de JFS partitie niet meer vanuit Linux benaderen kunt. Dat kan alleen met een blokgrootte van 4 KiB waarin een WPS URL object van 40 bytes in 8 kiloBytes (4 kB voor de 0,04 KiB data en 4 KiB of een meervoud hiervan voor maximaal maar zelden bereikte 64 KiB OS/2 EAs) wordt opgeslagen.
JFS Cookbook: Toen dit geschreven werd (16 October 2001) waren er nog allerlei JFS problemen.
OS/2 Filesystem Shootout : A Tale of Intrigue and Discovery by Michal Necasek, March 2002
http://www.madbrain.com/software/fill.zip
Very poor JFS write I/O performance compared to HPFS (JFS 20x slower)
Maar Installing eComStation on a JFS Volume is nu een reële optie.
Wikipedia.org: JFS (file system)
Wikipedia.org: Cache algorithms
REXX script to write cstats.exe output to g:\var\log\cstats01.csv.
/* schrijf cst/* schrijf cstats uitvoer naar logfile */
parse arg commentaar
logfile = 'g:\var\log\cstats01.csv'
CALL RxFuncAdd "SysLoadFuncs", "REXXUTIL", "SysLoadFuncs"
CALL SysLoadFuncs
firstline = 0
do forever /* herhaal dit tot op ctrl-break wordt gedrukt */
/* leeg de queue */
do while queued() > 0
junk = linein('queue:')
end
i = 0; cstats. = ''
'@cstats.exe | RXQUEUE'
do while queued() > 0
i = i + 1
cstats.i = strip(linein('queue:'))
end
cstats.0 = i
do forever
rc = stream(logfile, 'c', 'open write')
if rc = 'READY:' then leave
call syssleep 1
end
/* laat in eerste regels van bestand de layout zien */
if firstline = 0 then do
/* evt. meegegeven parameters als commentaar loggen */
if commentaar >< '' then call lineout logfile, commentaar
/* toevoegen regel met kolomnamen */
line = '"date","time'
/* cstats uitvoer in de logfile schrijven */
do i = 1 to cstats.0
line = line || '","' || word(cstats.i,1) || '","' || word(cstats.i, 3)
end
line = line || '"'
call lineout logfile, line
firstline = 1
end